TITLE: Pooling the Convolutional Layers in Deep ConvNets for Action Recognition
AUTHOR: Zhao, Shichao and Liu, Yanbin and Han, Yahong and Hong, Richang
FROM: arXiv:1511.02126
CONTRIBUTIONS
- Propose an efficient video representation framework basing on VGGNet and Two-Stream ConcNets.
- Trajectory pooling and line pooling are used together to extract features from convolutional layers.
- A frame-diff layer is used to get local descriptors.
METHOD
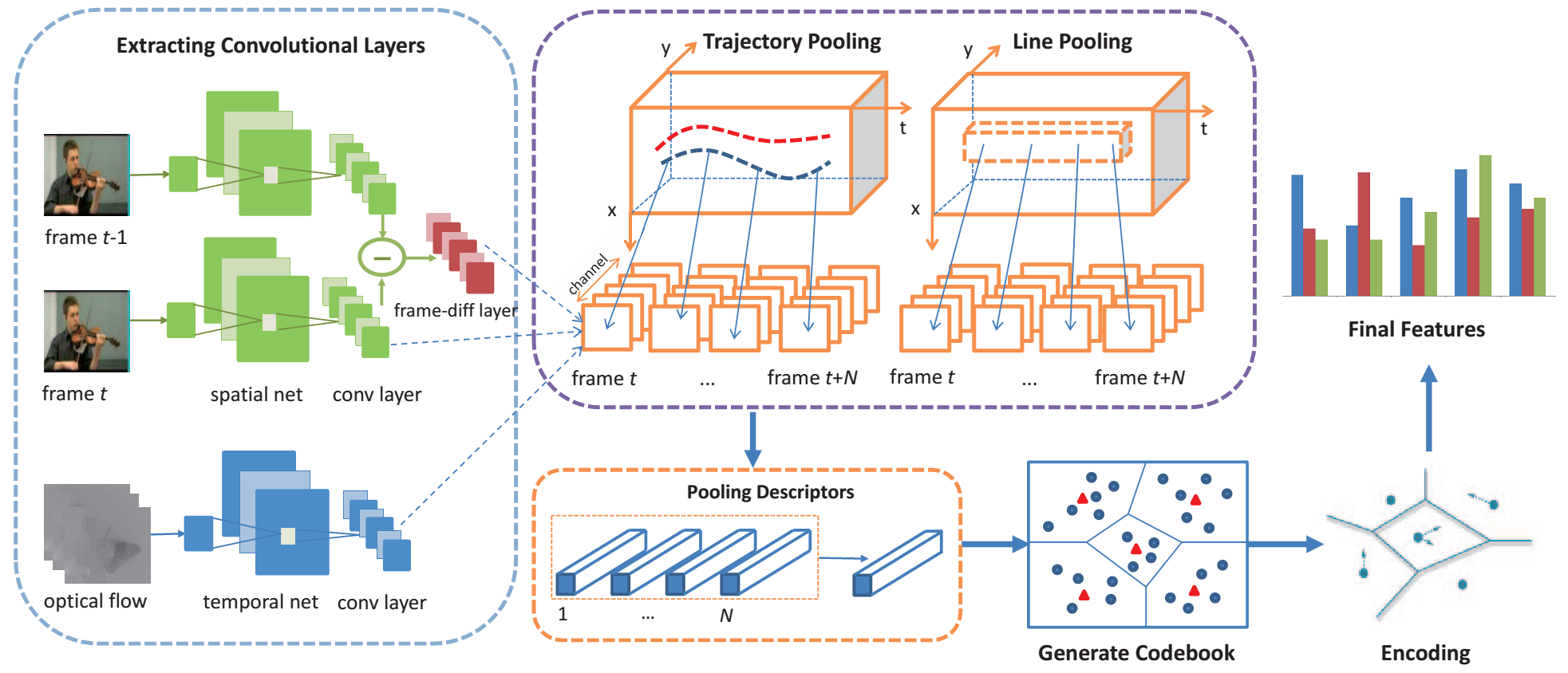
- Two succession frames are sent to a siamese VGGNet and a frame-diff layer is used to extract spatial features.
- Compute temporal feature in one frame using optical-flow net of Two-Stream ConvNet.
- Extract features in ConvNet feature maps along point trajectories or along lines in a dense sampling manner.
- Use BoF method to generate video representation
- Classify video using a SVM classifier.
ADVANTAGES
- Using deeper network to extract features, which are more discriminative.
- Different from Two-Stream ConvNet, in this work spatial features are extracted on every frame, which would provide more information.
DISADVANTAGES
- The two branches are trained independently. Jointly training in a multi-task manner may benefit.
OTHERS
- The difficulty of human action recognition is caused by some inherent characteristics of action videos such as intra-class variation, occlusions, view point changes, background noises, motion speed and actor differences.
- Despite the good performance, Dense Trajectory based action recognition algorithms suffer from huge computation costs and large disk affords.