TITLE: SuperCNN: A Superpixelwise Convolutional Neural Network for Salient Object Detection
AUTHER: Shengfeng He, Rynson W.H. Lau, Wenxi Liu, Zhe Huang, Qingxiong Yang Reid, Ian
FROM: IJCV2015
CONTRIBUTIONS
- A novel superpixel-wise convolutional neural network approach is proposed.
- Two kinds of sequence code are designed as input feature to CNN.
METHOD
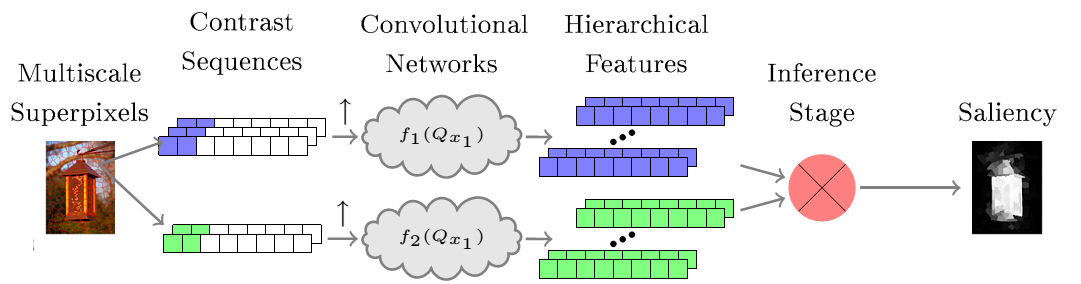
- Superpixels are extracted via some methods such as oversegmentation.
- Extract Color Uniqueness Sequences (CU) for each superpixels to describe the color contrast between regions.
- Extract Color Distribution Sequences (CD) for each superpixels to measure the color compactness of colors.
- The two sequences are fed into a CNN to generate two saliency maps.
- A regressor is used to merge the two predicted saliency maps
SOME DETAILS
Color Uniqueness Sequence is used to describe the color contrast of a Region. Given an image $I$ and the superpixels or regions \(R=\lbrace r_{1},…,r_{x},…,r_{N} \rbrace\), each region \(r_{x}\) contains a color uniqueness sequence $Q_{x}^{C} = \lbrace q_{1}^{c},…,q_{j}^{c},…,q_{N}^{c} \rbrace$. Each element, \(q_{x}^{c}\) is defined as
$$ q_{x}^{c} = t(r_{j})\cdot \vert C(r_{x})-C(r_{j}) \vert \cdot w(P(r_{x}),P(r_{j})) $$
where \(t(r_{j})\) counts the total number of pixels in region \(r_{j}\). \(\vert C(r_{x})-C(r_{j}) \vert\) is a 3D vector storing the absolute differences of each color channel. \(P(r_{x}\) is the mean position of region \(r_{j}\) and \(w(P(r_{x}),P(r_{j}))\) is defined as
$$ w(P(r_{x}),P(r_{j}))=exp(- \frac{1}{2\sigma_{s}^{2}}\Vert P(r_{x})-P(r_{j}) \Vert^{2} ) $$
The sequence \(Q_{x}^{C}\) is sorted by the spatial distance to region \(r_{x}\).
Color Distribution Sequence is a sequence \(Q_{x}^{D} = \lbrace q_{1}^{d},…,q_{j}^{d},…,q_{N}^{d} \rbrace\) with the element \(q_{j}^{d}\) defined as:
$$ q_{j}^{d} = t(r_{j})\cdot \vert P(r_{x})-P(r_{j}) \vert \cdot w(C(r_{x}),C(r_{j})) $$
where
$$ w(C(r_{x}),C(r_{j}))=exp(- \frac{1}{2\sigma_{s}^{2}}\Vert C(r_{x})-C(r_{j}) \Vert^{2} ) $$
the sequence is also sorted by the spatial distance.
Network Structure is briefly illustrated as below:

Saliency Inference is first to get the \(N\) predicted saliency scores of the \(N\) regions. Because of the two kinds of sequences, two sets of scores \(S_{1} and S_{2}\) are predicted. The final saliency map can be obtained by:
$$ S(r_{x})=\prod_{u\in \lbrace 1,2\rbrace}v_c^{u} \cdot S_{u}(r_{x}) $$
ADVANTAGES
- It is fast when infering.
- Large context are encoded in the sequences.
DISADVANTAGES
- The CNN is of a very light-weight structure. Deeper network may provide better performance.
- As the sequences are used to describe contrast information, which may lead to failure with the foreground and background having similar colors.