TITLE: R-FCN: Object Detection via Region-based Fully Convolutional Networks
AUTHER: Jifeng Dai, Yi Li, Kaiming He, Jian Sun
ASSOCIATION: MSRA, Tsinghua University
FROM: arXiv:1605.06409
CONTRIBUTIONS
- A framework called Region-based Fully Convolutional Network (R-FCN) is develpped for object detection, which consists of shared, fully convolutional architectures.
- A set of position-sensitive score maps are introduced to enalbe FCN representing translation variance.
- A unique ROI pooling method is proposed to shepherd information from metioned score maps.
METHOD
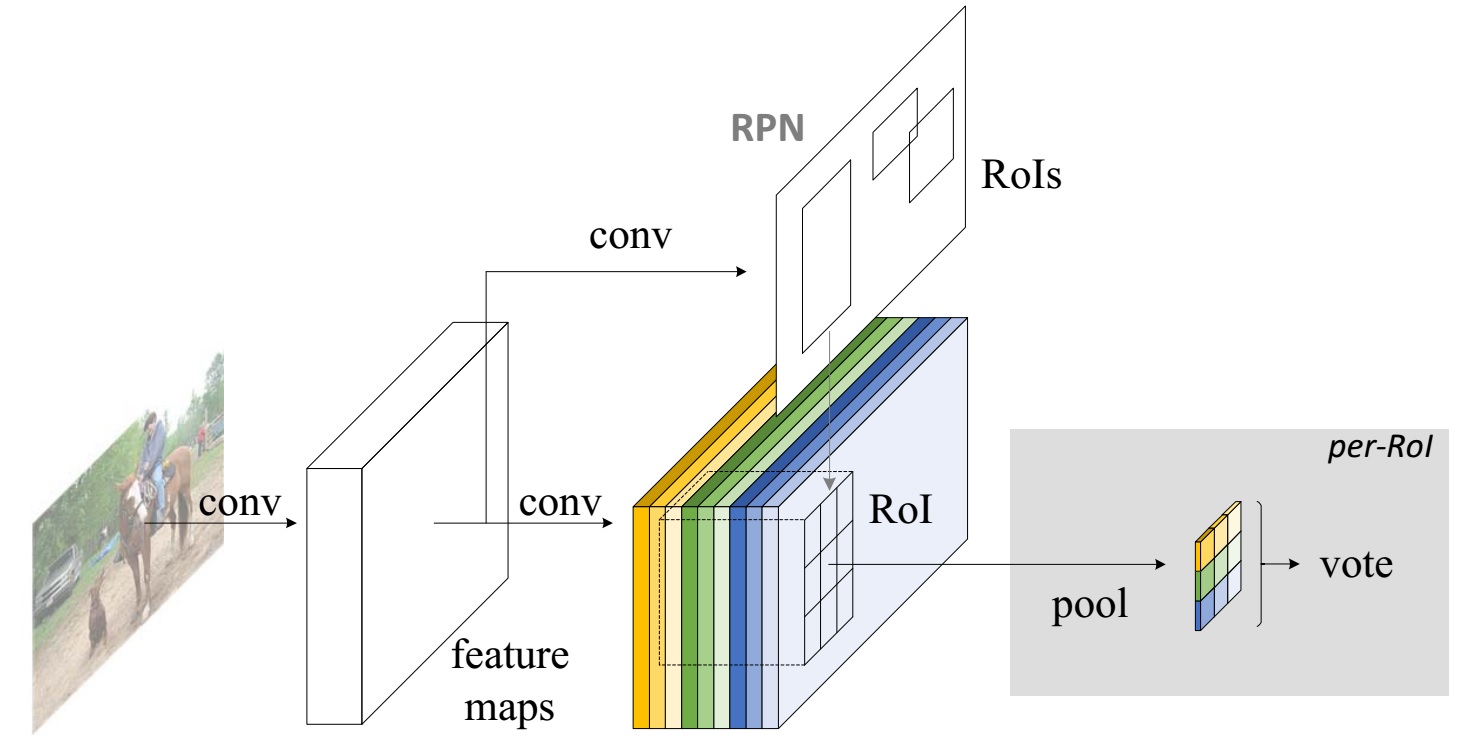
- The image is processed by a FCN manner network.
- At the end of FCN, a RPN (Region Proposal Network) is used to generate ROIs.
- On the other hand, a score map of $k^{2}(C+1)$ channels is generated using a bank of specialized convolutional layers.
- For each ROI, a selective ROI pooling is utilized to generate a $C+1$ channel score map.
- The scores in the score map are averaged to vote for category.
- Another $ 4k^2 $ dim convolutional layer is learned for bounding box regression.
Training Details
- R-FCN is trained end-to-end with pre-computed region proposals. Both category and position are learnt with the loss function $L(s,t_{x,y,w,h})=L_{cls}(s_{c})+\lambda[c>0]L_{reg}(t)$
- For each image, N proposals are generated and B out of N proposals are selected to train weights according to the highest losses. B is set to 128 in this work.
- 4-step alternating training is utilized to realizing feature sharing between R-FCN and RPN.
ADVANTAGES
- It is fast (170ms/image, 2.5-20x faster than Faster R-CNN).
- End-to-end training is easier to process.
- All learnable layers are convolutional and shared on the entire image, yet encode spatial information required for object detection.
DISADVANTAGES
- Compared with Single Shot methods, more computation resource is needed.