TITLE: Learning Deconvolution Network for Semantic Segmentation
AUTHER: Hyeonwoo Noh, Seunghoon Hong, Bohyung Han
ASSOCIATION: Department of Computer Science and Engineering, POSTECH, Korea
FROM: arXiv:1505.04366
CONTRIBUTIONS
- A multi-layer deconvolution network is designed and learned, which is composed of deconvolution, unpooling, and rectified linear unit (ReLU) layers.
- Instance-wise segmentations are merged for final sematic segmentation, which is free from scale issues.
METHOD
The main steps of the method is as follows:
- Object proposals are genereated by alogrithms such as EdgeBox.
- ROI extracted based on object proposals are sent to the Deconvolution Network. The outputs are instance-wise segmentations.
- instance-wise segmentations are combined to get the final segmentaton.
Some Details
Architecture of the network is shown as the following figure. In the network, unpooling operation captures example-specific structures by tracing the original locations with strong activations back to image space. On the other hand, deconvolution operation learnes filters to capture class-specific shapes.
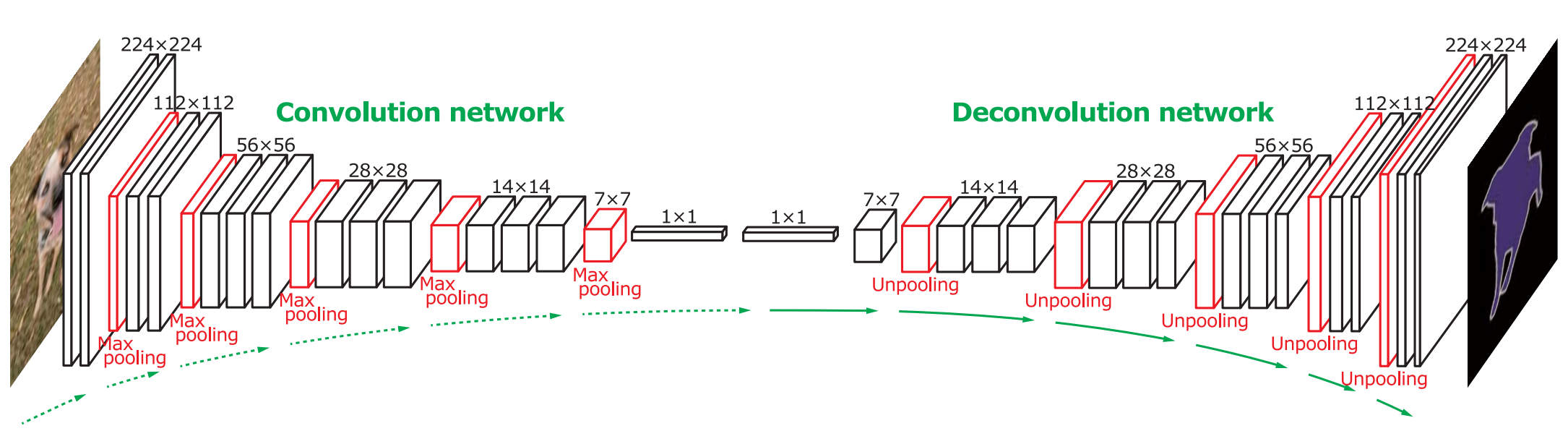
Training contains two stages. At first stage, simpler data are used to train the network. The simpler data are generated using object annotations and contains constraint appearance of objects. At second stage, complex data are similarly generated but from object proposals.
Inference includes a CRF can further bootstrap the performance.
ADVANTAGES
- It handles objects in various scales effectively and identifies fine details of objects .
- Deconvolution can generate finer segmentations.
DISADVANTAGES
- Large number of proposals are needed to get better result, which means higher computational complexity.