TITLE: ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
AUTHER: Adam Paszke, Abhishek Chaurasia, Sangpil Kim, Eugenio Culurciello
ASSOCIATION: University of Warsaw, Purdue University
FROM: arXiv:1606.02147
CONTRIBUTIONS
- A novel deep neural network architecture named ENet (efficient neural network) is propsed, which is quite efficient.
- A serie of designing strategies is discussed.
Design Choices
Network Architecture
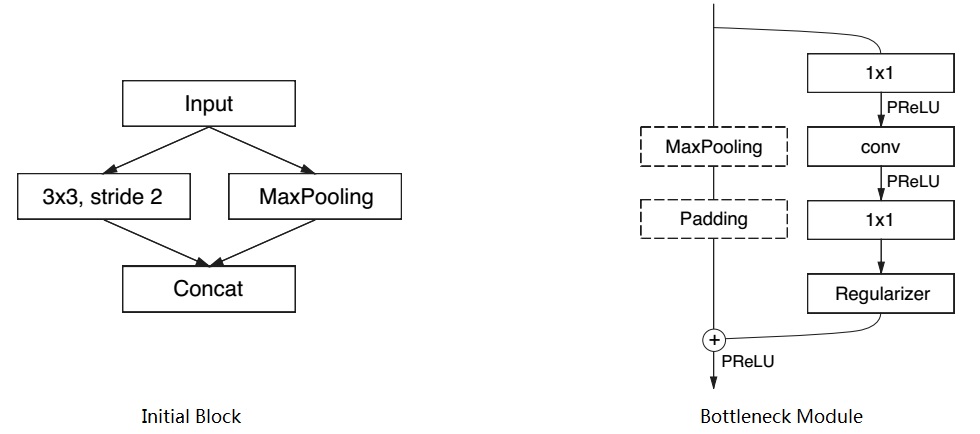
Readers could refer to the paper to have a look at the network architecture. The network is inspired by ResNet structure, while the authers re-design it based on the specific task of semantic segmentation and their intuitions. The intial block and basic building block (bottlenect module) is shown in the following figure. After the intial block, a comparetively large encoder is constructed using the bottleneck module. On the other hand, a smaller decoder follows the encoder.
Design Strategy
- Feature map resolution: Small feature map resolution has two drawbacks 1) loss of finer information of edges and 2) smaller size compared with original image. The advantage is that small feature map resolution means larger receptive field and more context for the filters. The first problem is solved by adding more feature maps or unsampling technique.
- Early downsampling: Early downsampling is very helpful for boosting the efficiency of the network while persisting the performance. The idea is that visual information is highly redundant and that initial network layers should not directly contribute to classification but act as good feature extractors.
- Decoder size: In most previous works, the encoder and decoder have the same size, for example totally symmetric. In this work, the auther uses a larger encoder and a smaller decoder. The responsibility of encoder is to operate on smaller resolution data and provide for information processing and filtering. Instead, the role of the the decoder, is to upsample the output of the encoder, only fine-tuning the details.
- Nonlinear operations In this paper some interesting observations are carried out. The auther invetigates the effect of nonlinear operations by training the network using PReLU. All layers in the main branch behave nearly exactly like regular ReLUs, while the weights of PReLU inside bottleneck modules are negative. It means that typical identity shortcut in ResNet does not work well because of the limited depth of the network.
- Information-preserving dimensionality changes: A method of performing pooling operation in parallel with a convolution of stride 2 and concatenating resulting feature maps is used to guarentee efficiency and performance, just as the intial block shows.
- Factorizing filters: Using factorizing technique can achive a kernel of larger size while using less computations. In addition, deeper network and more times of non-linear operation helps simulate richer functions.
- Dilated convolutions: Dilated convolutions is a good way of maintaining feature resolution while boosting efficiency.
- Regularization: Spatial Dropout is used to prevent overfitting.
ADVANTAGES
- The network processes fast.
DISADVANTAGES
- The performance is comparatively inferior.