TITLE: Face Detection with End-to-End Integration of a ConvNet and a 3D Model
AUTHOR: Yunzhu Li, Benyuan Sun, Tianfu Wu, Yizhou Wang
ASSOCIATION: Peking University, North Carolina State University
FROM: arXiv:1606.00850
CONTRIBUTIONS
- It presents a simple yet effective method to integrate a ConvNet and a 3D model in an end-to-end learning with multi-task loss used for face detection in the wild.
- It addresses two limitations in adapting the state-of-the-art faster-RCNN for face detection: eliminating the heuristic design of anchor boxes by leveraging a 3D model, and replacing the generic and predefined RoI pooling with a configuration pooling which exploits the underlying object structural configurations.
- It obtains very competitive state-of-the-art performance in the FDDB and AFW benchmarks.
METHOD
The main scheme of inferring is shown in the following figure.
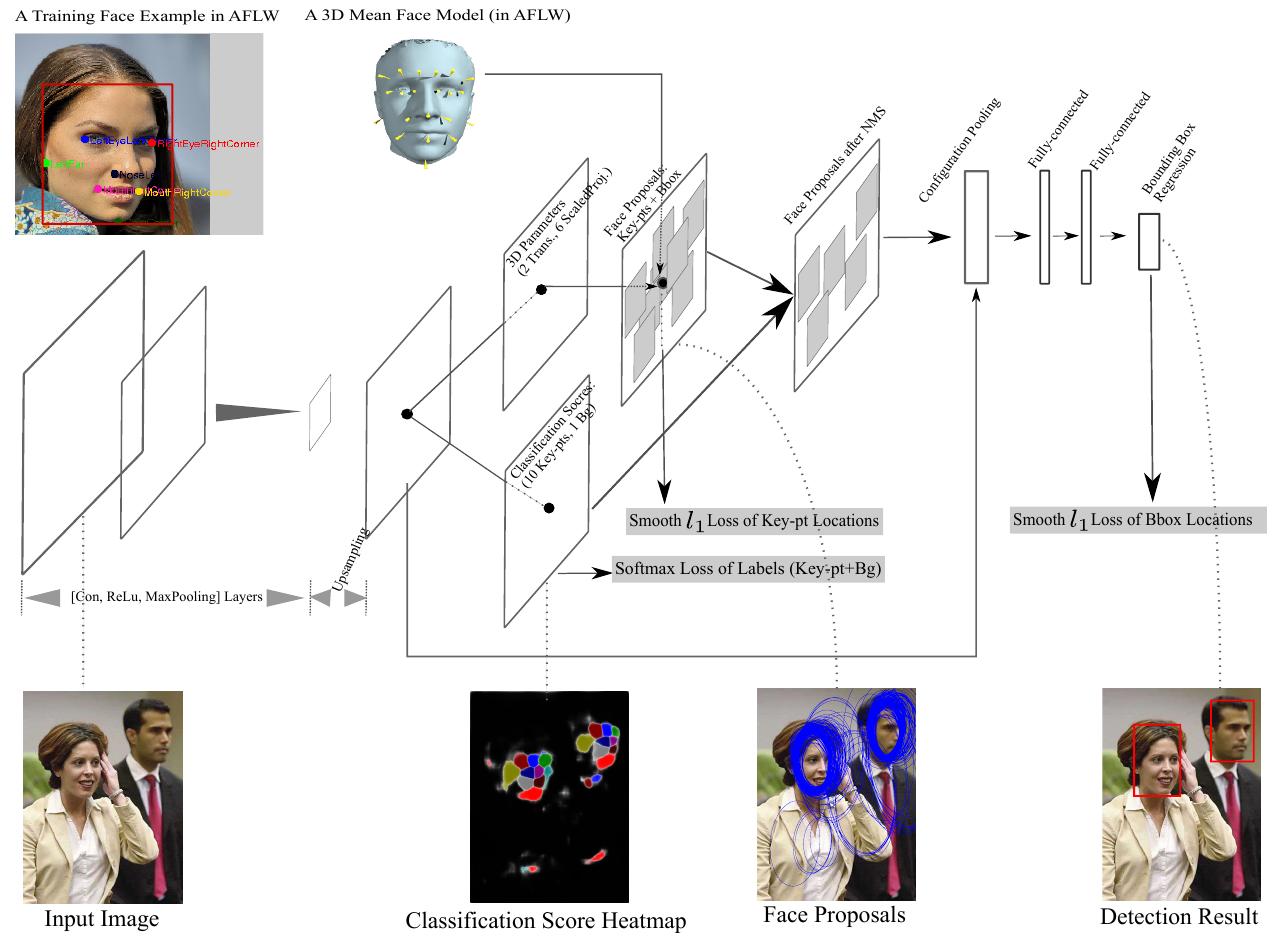
The input image is sent into a ConvNet, e.g. VGG, with an upsampling layer. Then the network will generate face proposals based on the score of summing the log probability of the keypoints, which is predicted by the predefined 3D face model.
some details
The loss of keypoint labels is defined as
$$ L_{cls}(\omega)= -{1 \over 2m} \sum_{i=1}^{2m} \log(p_{l_i}^{\mathbf{x}_i}) $$
where $\omega$ stands for the learnable weights of ConvNet, $m$ is the number of the keypoints, and $p_{l_i}^{\mathbf{x}_i}$ is the probability of the point in location $\mathbf{x}_i$, which can be obtained by annotations, belongs to label $l_i$.
The loss of keypoit locations is defined as
$$ L_{loc}^{pt}(\omega)={1 \over m^2} \sum_{i=1}^m \sum_{i=1}^m \sum_{t \in {x,y}} Smooth(t_i-\hat{t}_{i,j}) $$
where $smooth(\cdot)$ is the smooth $l_1$ loss. For each ground-truth keypoint, we can generate a set of predicted keypoints based on the 3D face model and the 3D transformation parameters. If for each face we have $m$ keypoints, then we will generate m sets of predicted keypoints. For each keypoint, m locations will be predicted.
The Configuration Pooling Layer is similar to the ROI Pooling Layer in faster-RCNN. Features are extracted based on the locations and relations of the keypoints, rather than based on the predefined perceptive field.