TITLE: Training Region-based Object Detectors with Online Hard Example Mining
AUTHOR: Abhinav Shrivastava, Abhinav Gupta, Ross Girshick
ASSOCIATION: Carnegie Mellon University, Facebook AI Research
FROM: arXiv:1604.03540
CONTRIBUTIONS
A novel bootstrapping technique called online hard example mining (OHEM) for training state-of-the-art detection models based on deep ConvNets is proposed. The algorithm is a simple modification to SGD in which training examples are sampled according to a non-uniform, non-stationary distribution that depends on the current loss of each example under consideration.
METHOD
Online Hard Example Mining
The main idea of the OHEM is illustrated in the following figure:
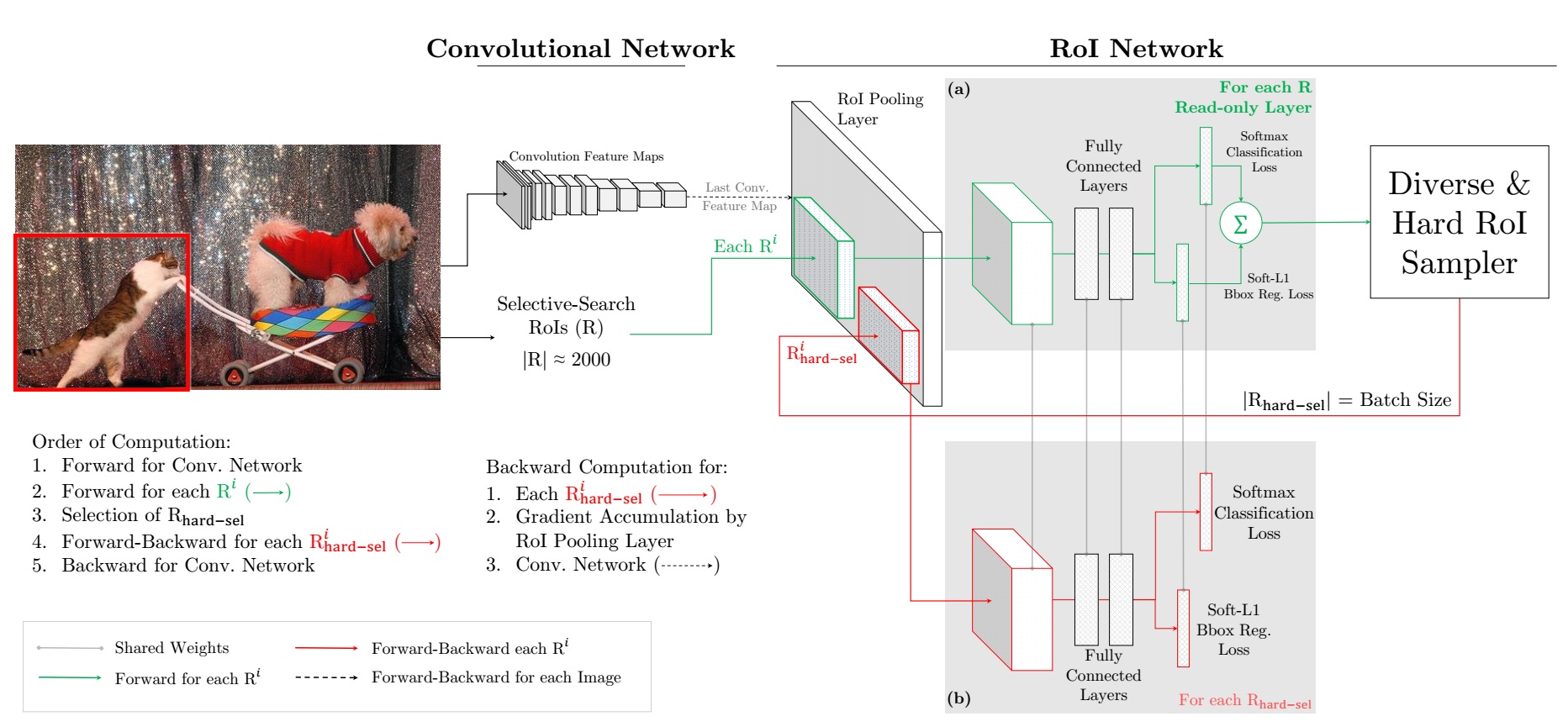
This alogorithm is designed for region proposal based object detector. The top side of the figure, including the Convolutional Network and the green arrows part of the RoI Network is same with Fast-RCNN. The key of the algorithm lies in the red arrows part of the RoI Network.
For an input image at SGD iteration, a conv feature map using the Convolutional Network is first computed. Then the RoI Network uses this feature map and the all the input RoIs, instead of a sampled mini-batch, to do a forward pass. The loss computated for each RoI represents how well the current network performs on each RoI. Hard examples are selected by sorting the input RoIs by loss and taking the B/N examples for which the current network performs worst.
Some Details
The author’s implementation maintains two copies of the RoI network, one of which is readonly. This implies that the readonly RoI network allocates memory only for forward pass of all RoIs (R) as opposed to the standard RoI network, which allocates memory for both forward and backward passes. For an SGD iteration, given the conv feature map, the readonly RoI network performs a forward pass and computes loss for all input RoIs (green arrows). Then the hard RoI sampling module selects hard examples, which are input to the regular RoI network (red arrows). This network computes forward and backward passes only for hard RoIs, accumulates the gradients and passes them to the conv network. In practice, the author uses all RoIs from all N images as R, therefore the effective batch size for the readonly RoI network is $\vert R \vert$ and for the regular RoI network is the standard B.
ADVANTAGE
- It removes the need for several heuristics and hyperparameters commonly used in region-based ConvNets.
- It yields a consistent and significant boosts in mean average precision.
- Its effectiveness increases as the training set becomes larger and more difficult, as demonstrated by results on the MS COCO dataset.
SOME IDEAS
- How to apply data balancing in one-shot method, such as SSD?