TITLE: Aggregated Residual Transformations for Deep Neural Networks
AUTHOR: Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He
ASSOCIATION: UC San Diego, Facebook AI Research
FROM: arXiv:1611.05431
CONTRIBUTIONS
A simple, highly modularized network (ResNeXt) architecture for image classification is proposed. The network is constructed by repeating a building block that aggregates a set of transformations with the same topology.
METHOD
The network is designed with two simple rules inspired by VGG/ResNets:
- if producing spatial maps of the same size, the blocks share the same hyper-parameters (width and filter sizes).
- each time when the spatial map is downsampled by a factor of 2, the width of the blocks is multiplied by a factor of 2. The second rule ensures that the computational complexity, in terms of FLOPs is roughly the same for all blocks.
The building block of ResNeXt is shown in the following figure:
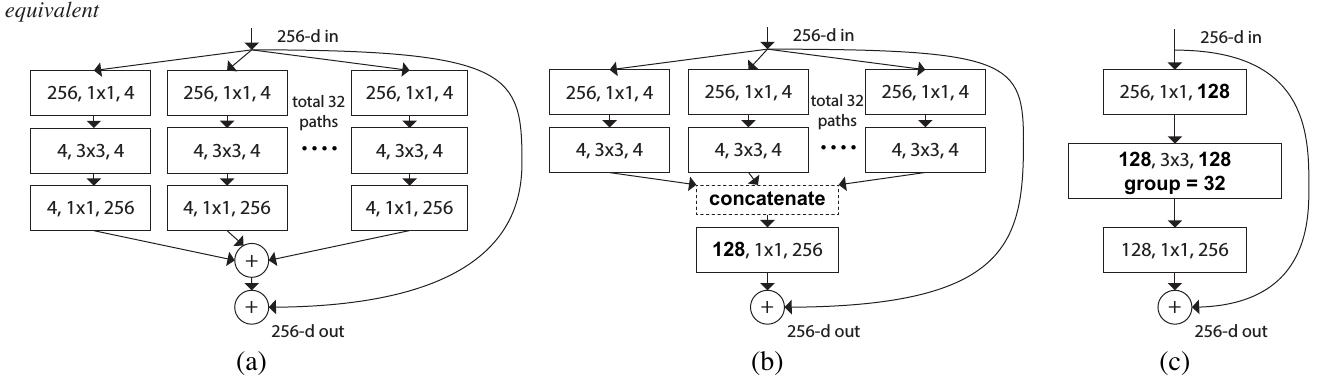
Such design will make the network having more channels (sets of transformations) without increasing much FLOPs, which is claimed as the increasing of ardinality.
SOME IDEAS
The explanation of why such designation can lead to better performance seems to be less pursative.