TITLE: Speed/accuracy trade-offs for modern convolutional object detectors
AUTHOR: Jonathan Huang, Vivek Rathod, Chen Sun, Menglong Zhu, Anoop Korattikara, Alireza Fathi, Ian Fischer, Zbigniew Wojna, Yang Song, Sergio Guadarrama, Kevin Murphy
ASSOCIATION: Google Research
FROM: arXiv:1611.10012
CONTRIBUTIONS
In this paper, the trade-off between accuracy and speed is studied when building an object detection system based on convolutional neural networks.
Summary
Three main families of detectors — Faster R-CNN, R-FCN and SSD which are viewed as “meta-architectures” are considered. Each of these can
be combined with different kinds of feature extractors, such as VGG, Inception or ResNet. other parameters, such as the image resolution, and the number of box proposals are also varied to compare how they perform in the task of detecting objects. The main findings are summarized as follows.
Accuracy vs time
The following figure shows the accuracy vs time of different configurations.
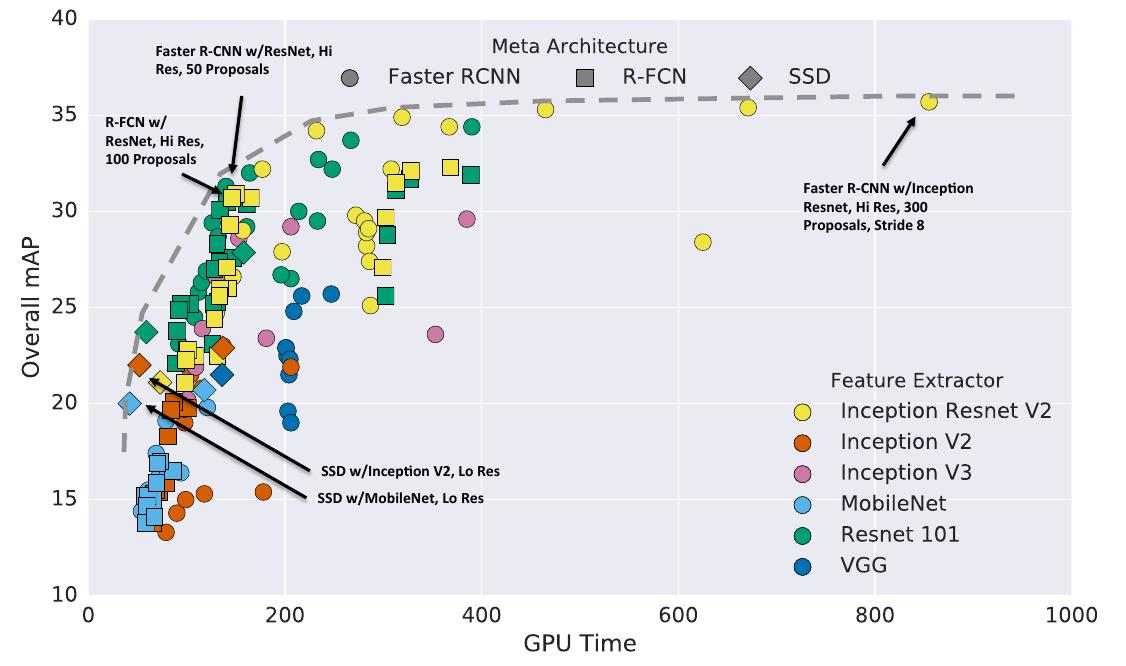
Generally speaking, R-FCN and SSD models are faster on average while Faster R-CNN tends to lead to slower but more accurate models, requiring at least 100 ms per image.
Critical points on the optimality frontier
- SSD models with Inception v2 and Mobilenet feature extractors are most accurate of the fastest models.
- R-FCN models using Residual Network feature extractors which seem to strike the best balance between speed and accuracy.
- Faster R-CNN with dense output Inception Resnet models attain the best possible accuracy
The effect of the feature extractor
There is an intuition that stronger performance on classification should be positively correlated with stronger performance detection. It is true for Faster R-CNN and R-FCN, but it is less apparant for SSD as the following figure illustrated.
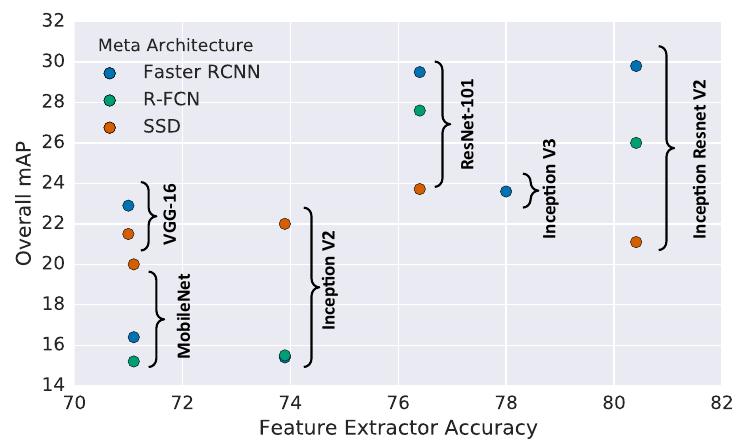
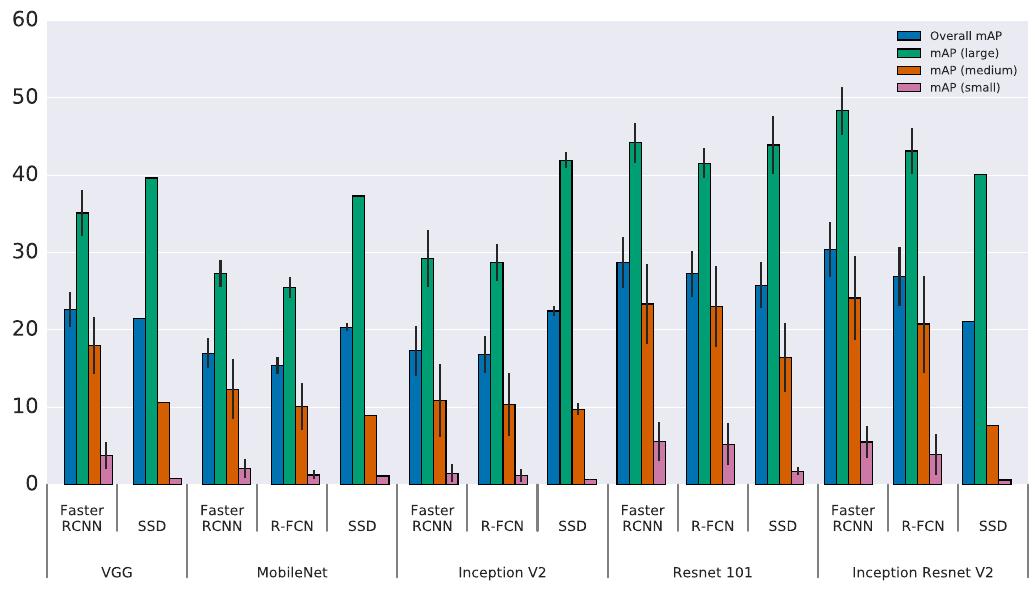
The effect of object size
Not surprisingly, all methods do much better on large objects. Even though SSD models typically have (very) poor performance on small objects, they are competitive with Faster RCNN and R-FCN on large objects, even outperforming these meta-architectures for the faster and more lightweight feature extractors as the following figure illustrated.
The effect of image size
Decreasing resolution by a factor of two in both dimensions consistently lowers accuracy (by 15.88% on average) but also reduces inference time by a relative factor of 27.4% on average.
Strong performance on small objects implies strong performance on large objects, but not vice-versa as SSD models do well
on large objects but not small.
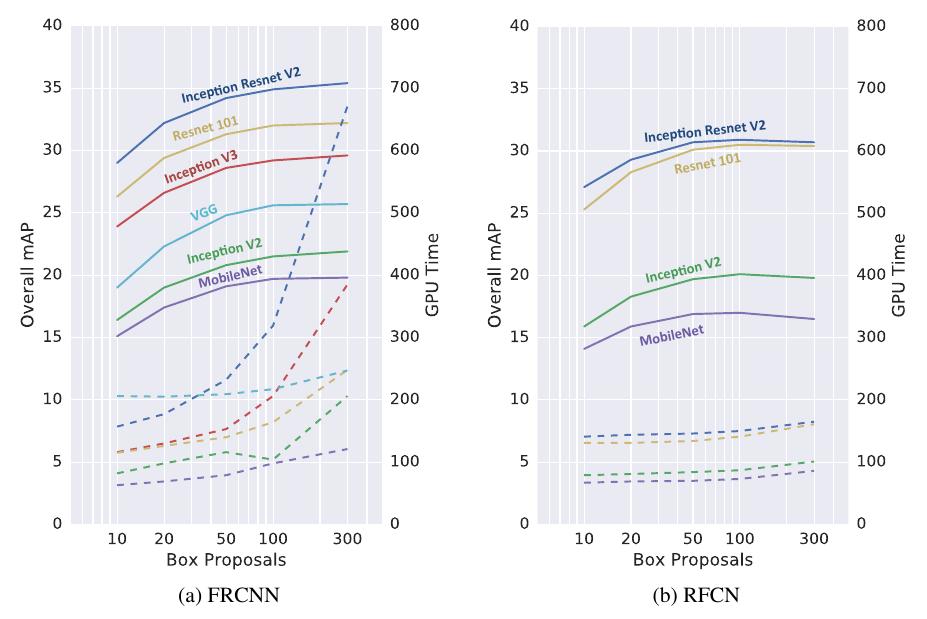
The effect of the number of proposals
For Faster R-CNN, reducing proposals help accelerating prediction significantly because the computation of box classifier is correlated with the number of the proposals. The interesting thing is that Inception Resnet, which has 35.4% mAP with 300 proposals can still have surprisingly high accuracy (29% mAP) with only 10 proposals. The sweet spot is probably at 50 proposals.
For R-FCN, computational savings from using fewer proposals are minimal, because the box classifier is only run once per image. At 100 proposals, the speed and accuracy for Faster R-CNN models with ResNet becomes roughly comparable to that of equivalent R-FCN models which use 300 proposals in both mAP and GPU speed.
The following figure shows the observation, in which solid lines shows the relation between number of proposals and mAP, while dotted lines shows that of GPU inference time.
Others
The paper also discussed the FLOPs and Memories. The observations in these parts are sort of obvious for the practitioner. Another observation is that Good localization at .75 IOU means good localization at all IOU thresholds.