TITLE: Wider or Deeper: Revisiting the ResNet Model for Visual Recognition
AUTHOR: Zifeng Wu, Chunhua Shen, Anton van den Hengel
ASSOCIATION: The University of Adelaide
FROM: arXiv:1611.10080
CONTRIBUTIONS
- A further developed intuitive view of ResNets is introduced, which helps to understand their behaviours and find possible directions to further improvements.
- A group of relatively shallow convolutional networks is proposed based on our new understanding. Some of them achieve the state-of-the-art results on the ImageNet classification dataset.
- The impact of using different networks is evaluated on the performance of semantic image segmentation, and these networks, as pre-trained features, can boost existing algorithms a lot.
SUMMARY
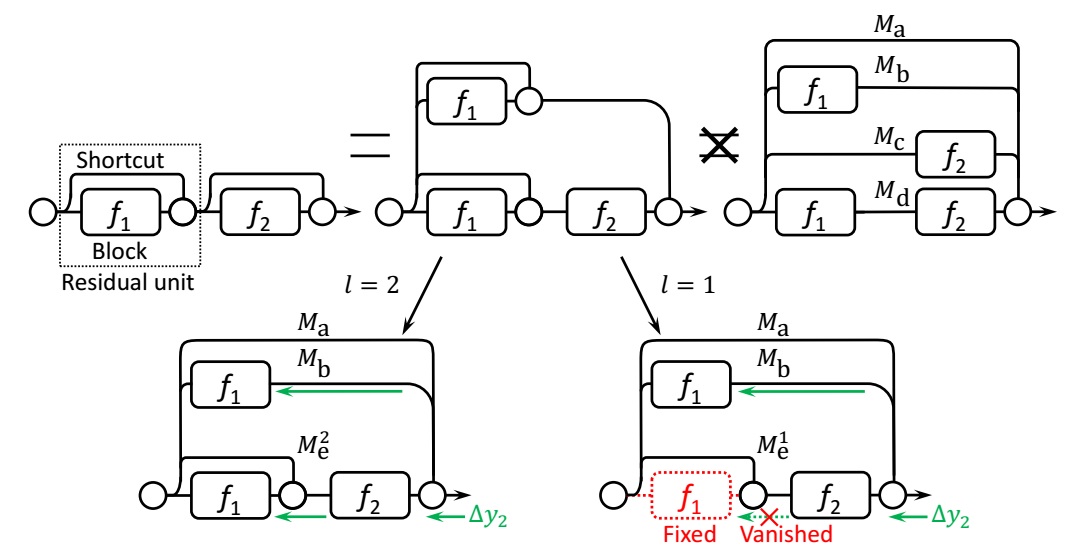
For the residual $unit \ i$, let $y_{i-1}$ be the input, and let $f_{i}(\cdot)$ be its trainable non-linear mappings, also named $Blok \ i$. The output of $unit \ i$ is recursively defined as
$$ y_{i} = f_{i}(y_{i-1}, \omega_{i})+y_{i-1} $$
where $\omega_{i}$ denotes the trainalbe parameters, and $f_{i}(\cdot)$ is often two or three stacked convolution stages in a ResNet building block. Then top left network can be formulated as
$$ y_{2} = y_{1}+f_{2}(y_{1},\omega_{2}) $$
$$ = y_{0}+f_{1}(y_{0},\omega_{1})+f_{2}(y_{0}+f_{1}(y_{0}, \omega_{1}, \omega_{2}) $$
Thus, in SGD iteration, the backward gradients are:
$$ \Delta \omega_{2}=\frac{df_{s}}{d\omega_{2}}\cdot \Delta y_{2} $$
$$ \Delta y_{1}= \Delta y_{2} + f_{2}^{‘} \cdot \Delta y_{2} $$
$$ \Delta \omega_{1} = \frac{df_{1}}{d \omega_{1}} \cdot \Delta y_{2}+ \frac{df_{1}}{d \omega_{1}} \cdot f_{2}^{‘} \cdot \Delta y_{2} $$
Ideally, when effective depth $l\geq2$, both terms of $\Delta \omega_{1}$ are non-zeros as the bottom-left case illustrated. However, when effective depth $l=1$, the second term goes to zeros, which is illustrated by the bottom-right case. If this case happens, we say that the ResNet is over-deepened, and that it cannot be trained in a fully end-to-end manner, even with those shortcut connections.
To summarize, shortcut connections enable us to train wider and deeper networks. As they growing to some point, we will face the dilemma between width and depth. From that point, going deep, we will actually get a wider network, with extra features which are not completely end-to-end trained; going wider, we will literally get a wider network, without changing its end-to-end characteristic.
The author designed three kinds of network structure as illustrated in the following figure
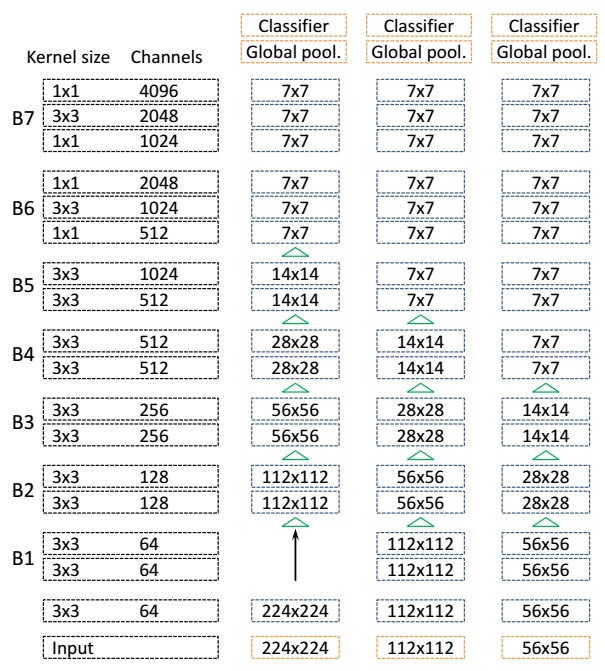
and the classification performance on ImageNet validation set is shown as below