TITLE: Convolutional Pose Machines
AUTHOR: Shih-En Wei, Varun Ramakrishna, Takeo Kanade, Yaser Sheikh
ASSOCIATION: CMU
FROM: arXiv:1602.00134
CONTRIBUTIONS
- learning implicit spatial models via a sequential composition of convolutional architectures
- a systematic approach to designing and training such an architecture to learn both image features and image-dependent spatial models for structured prediction tasks, without the need for any graphical model style inference.
METHOD
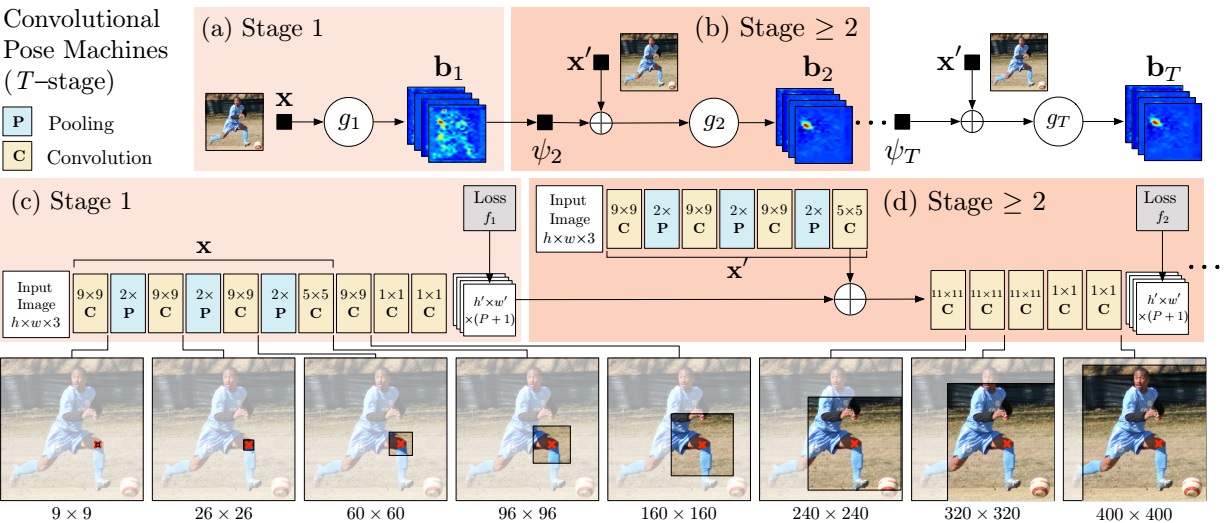
The following figure shows the comparison of traditional Pose Machine and Convolutional Pose Machine
Pose Machines
A pose machine consists of a sequence of multi-class predictors, $g_{t}(\cdot)$, that are trained to predict the location of each part in each level of the hierarchy. In each $stage$ $t \in {1…T}$, the classifiers $g_{t}$ predict beliefs for assigning a location to each part $Y_{p}=z, \forall z \in \mathbb{Z}$, where $\mathbb{Z}$ is the set of all locations in an image.
As illustrated in the figure (a) and (b), the image is first sent to $Stage$ $1$ and a belief map is predicted. Then the belief map and image features $x’$ are combined to sent to the following stage. As the procedure repeats, final result is predicted from the last $Stage$ $T$.
Convolutional Pose Machines
Convolutional Neural Network is naturally a sequence of stages if multiple losses and predictors are inserted at the intermediate layers. The (c) and (d) in the figure illustrated a convolutional pose machine. The sub-network in (c) plays the role of first stage. The shared network at the top-left corner in (d) is used to extract image features $x’$, which will be combined with the output of every $Stage$ $t-1$ and sent to $Stage$ $t$. In addition, the stacked convolutional layers’ perceptual field increases as deepening, which means that more contextual infomation is taken into consideration helping refine the output.
When training, every stage has its own loss function to predict parts. These losses work similar with the auxiliary classifiers in GoogleNet, which helps alleviate the problem caused by the vanishing of gradient. The network can be trained end-to-end. Compared with traditional pose machine, CMP is much easier to train. The visualization of the network can be found here