TITLE: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
AUTHOR: Zhe Cao, Tomas Simon, Shih-En Wei, Yaser Sheikh
ASSOCIATION: CMU
FROM: arXiv:1611.08050
CONTRIBUTIONS
- a method for multi-person pose estimation is proposed that approaches the problem in a bottom-up manner to maintain realtime performance and robustness to early commitment, but utilizes global contextual information in the detection of parts and their association.
- Part Affinity Fields (PAFs), a set of 2D vector fields, is presented, each of which encode the location and orientation of a particular limb at each position in the image domain.
METHOD
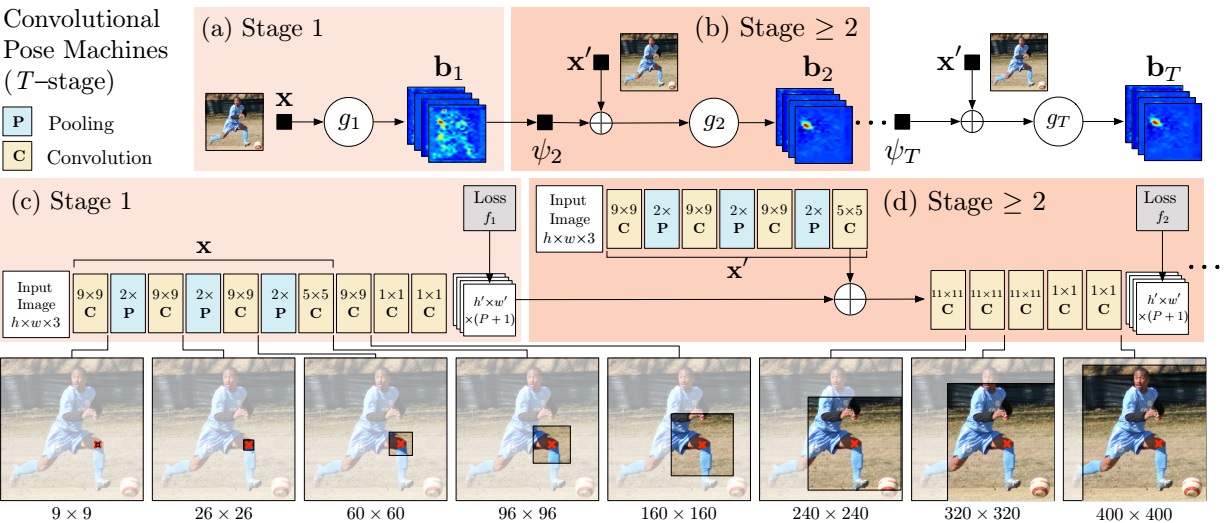
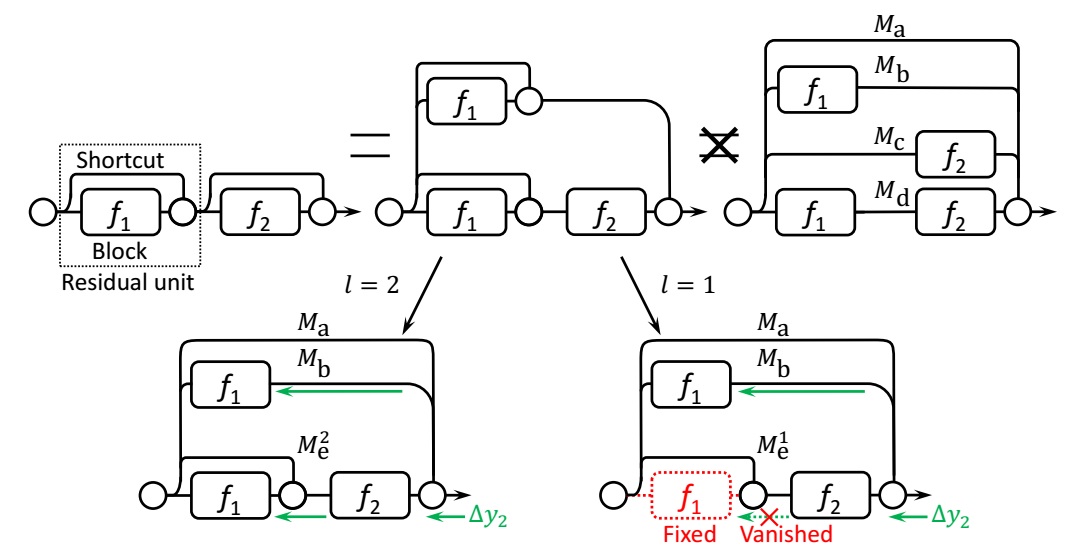
This work is the successor of Convolutional Pose Machines. The network structure, which predict the part emergence heatmap and part aafinity field jointly, is illustrated in the following figure. We can compare it with previous work.
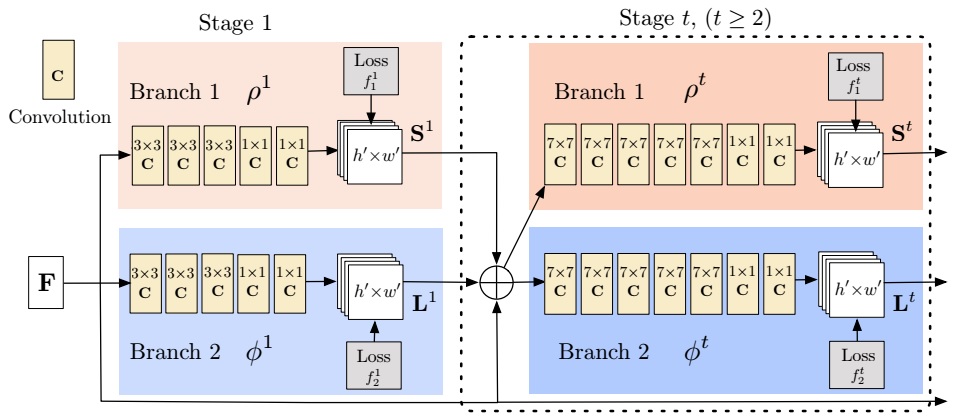
Similar with previous work, the network works as sequence learning scheme. One of the branch predicts confidence maps for part detection, while the other one predicts part affinity fields for part association.
Confidence Maps for Part Detection
At each location $ \mathbf{P} $, the value of the confidence $ S_{j}^{\ast}(\mathbf{P}) $ for a part type $ j $ is defined as
$$ S_{j}^{\ast}(\mathbf{P}) = \max \limits_{k} S_{j,k}^{\ast}(\mathbf{P}) $$
It means that for every type of part, a heatmap is predicted with multiple highlight areas, indicating the emergence of a part instance.
Part Affinity Fields for Part Association
If we consider a single limb, let $$ \mathbf{x}{j_1,k} $$ and $$ \mathbf{x}{j_{2},k} $$ be the position of body parts $$ j_{1} $$ and $$ j_{2} $$ from the limb class $$ c $$ for a person $$ k $$ on the image. $$ l_{c,k} = \Vert \mathbf{x}{j{2},k} - \mathbf{x}{j{1},k} \Vert_{2} $$ is the length of the limb, and $$ \mathbf{v} = l^{−1}{c,k}(\mathbf{x}{j_{2},k} - \mathbf{x}{j{1},k}) $$ is the unit vector in the direction of the limb. The ideal part affinity vector field, $$ L^{∗}_{c,k} $$, at an image point $$ \mathbf{P} $$ as
$$ \mathbf{L}^{\ast}_{c,k}(\mathbf{P}) = \begin{cases}
\mathbf{v}& \text{if } \mathbf{P} \text{ on limb } c,k \
\mathbf{0}& \text{otherwise}
\end{cases} $$
Similar to confidence maps for part detection, part affinity fields are also predicted for all persons
$$ \mathbf{L}^{\ast}{c}(\mathbf{P}) = \frac{1}{n{p}} \sum_{k} \mathbf{L}^{\ast}_{c,k}(\mathbf{P}) $$
where $$n_{p}$$ is the number of non-zero vectos at point $$\mathbf{P}$$. The confidence score of each limb candidate is measured by
$$ E = \int_{u=0}^{u=1} \mathbf{L}{c}(\mathbf{P}(u)) \cdot \frac{\mathbf{d}{j_{2}}-\mathbf{d}{j{1}}}{\Vert \mathbf{d}{j{2}}-\mathbf{d}{j{1}} \Vert_{2}}du $$
where $$\mathbf{d}{j{1}}$$ and $$\mathbf{d}{j{2}}$$ are two detected body parts.
Multi-Person Parsing using PAFs
The last problem is to select different limbs linked in PAFs to combine as one person’s skeleton. This is a classical generalized maximum clique problem. I think in additional to the method mentioned in this paper, many other optimiaztion algorithms can be tried. These algorithms are well discussed in multi-object tracking problem.