TITLE: LCNN: Lookup-based Convolutional Neural Network
AUTHOR: Hessam Bagherinezhad, Mohammad Rastegari, Ali Farhadi
ASSOCIATION: University of Washington, Allen Institute for AI
FROM: arXiv:1611.06473
CONTRIBUTIONS
LCNN, a lookup-based convolutional neural network is introduced that encodes convolutions by few lookups to a dictionary that is trained to cover the space of weights in CNNs.
METHOD
The main idea of the work is decoding the weights of the convolutional layer using a dictionary $D$ and two tensors, $I$ and $C$, like the following figure illustrated.
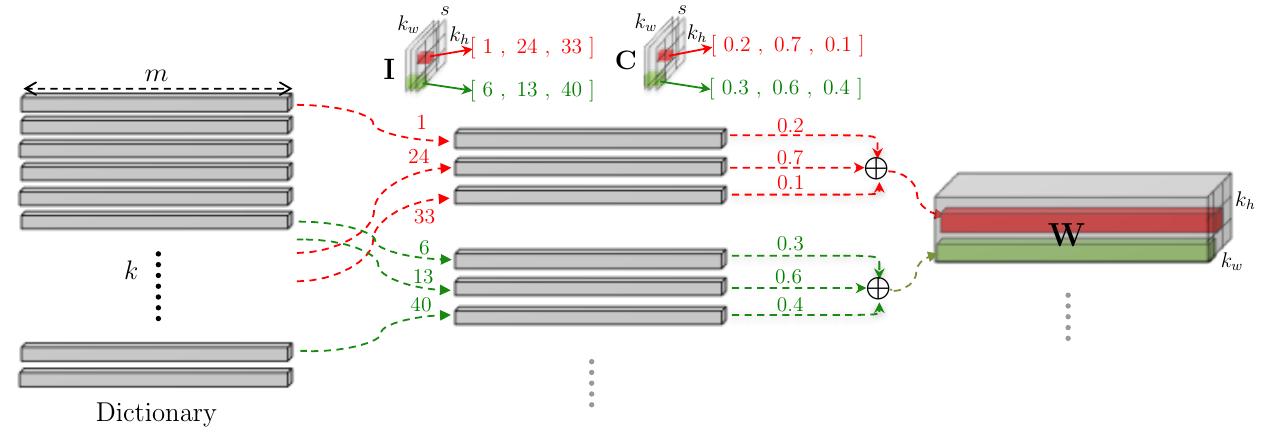
where $k$ is the size of the dictionary $D$, $m$ is the size of input channel. The weight tensor can be constructed by the linear combination of $S$ words in dictionary $D$ as follows:
$$ W_{[:,r,c]}=\sum_{t=1}^{S}C_{[t,r,c]}\cdot D_{[I_{[t,r,c]},:]} \forall r,c $$
where $S$ is the size of number of components in the linear combinations. Then the convolution can be computed fast using a shared dictionary. we can convolve the input with all of the dictionary vectors, and then compute the output according to $I$ and $C$. Since the dictionary $D$ is shared among all weight filters in a layer, we can precompute the convolution between the input tensor $\textbf{X}$ and all the dictionary vectors. Given $\textbf{S}$ which is defined as:
$$ \textbf{S}{[i,:,:]}=\textbf{X}*\textbf{D}{[i,:]} \forall 1\leq i \leq k $$
the convolution operation can be computed as
$$ \textbf{X} * \textbf{W} = \textbf{S} * \textbf{P} $$
where $\textbf{P}$ can be expressed by $I$ and $C$:
$$ P_{j,r,c} = \begin{cases}
C_{t,r,c}& \exists t:I_{t,r,c}=j \
0& \text{otherwise}
\end{cases} $$
The idea can be illustrated in the following figure:
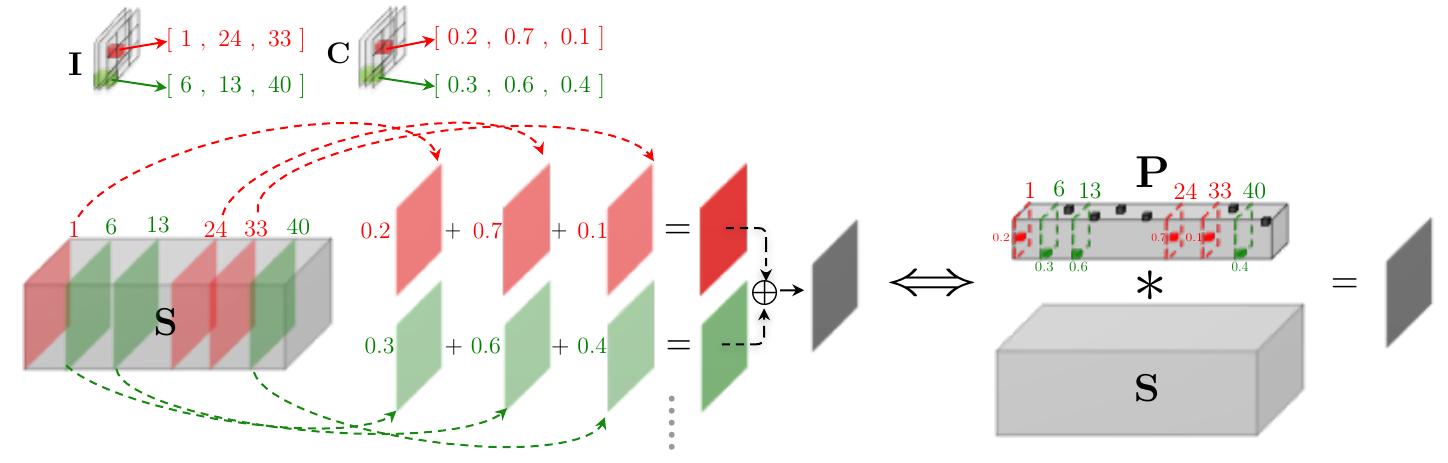
thus the the dictionary and the lookup parameters can be trained jointly.
ADVANTAGES
- It speeds up inference.
- Few-shot learning. The shared dictionary in LCNN allows a neural network to learn from very few training examples on novel categories
- LCNN needs fewer iteration to train.
DISADVANTAGES
- Performance is hurt because of the estimation of the weights