I am going to maintain this page to record a few things about computer vision that I have read, am doing, or will have a look at. Previously I’d like to write short notes of the papers that I have read. It is a good way to remember and understand the ideas of the authors. But gradually I found that I forget much portion of what I had learnt because in addition to paper I also derive knowledges from others’ blogs, online courses and reports, not recording them at all. Besides, I need a place to keep a list of what I should have a look at but do not at the time when I discover them. This page will be much like a catalog.
PAPERS AND PROJECTS
OBJECT/SALIENCY DETECTION
- EfficientDet: Scalable and Efficient Object Detection (PDF, Project/Code)
- YOLOv4: Optimal Speed and Accuracy of Object Detection (PDF, Project/Code)
- Learning Data Augmentation Strategies for Object Detection (PDF, Project/Code)
- Light-Weight RetinaNet for Object Detection (PDF)
- Objects as Points (PDF, Code/Projects)
- Augmentation for small object detection (PDF)
- ThunderNet: Towards Real-time Generic Object Detection (PDF)
- Pyramid Mask Text Detector (PDF)
- Gaussian YOLOv3: An Accurate and Fast Object Detector Using Localization Uncertainty for Autonomous Driving (PDF)
- CornerNet: Detecting Objects as Paired Keypoints (PDF, Code/Project, Reading Note)
- Scale-Aware Trident Networks for Object Detection (PDF)
- Acquisition of Localization Confidence for Accurate Object Detectinon (PDF, Project/Code)
- A Single Shot Text Detector with Scale-adaptive Anchors (PDF)
- Small-scale Pedestrian Detection Based on Somatic Topology Localization and Temporal Feature Aggregation (PDF)
- Object detection at 200 Frames Per Second (PDF, )
- DetNet: A Backbone network for Object Detection (PDF, Reading Note)
- Zero-Shot Object Detection (PDF)
- Unsupervised Discovery of Object Landmarks as Structural Representations (PDF, Project/Code)
- Cascade R-CNN: Delving into High Quality Object Detection (PDF, PROJECT/CODE)
- Path Aggregation Network for Instance Segmentation (PDF)
- ClickBAIT-v2: Training an Object Detector in Real-Time (PDF)
- Single-Shot Bidirectional Pyramid Networks for High-Quality Object Detection (PDF)
- Complex-YOLO: Real-time 3D Object Detection on Point Clouds (PDF)
- Zero-Shot Object Detection: Learning to Simultaneously Recognize and Localize Novel Concepts (PDF)
- Domain Adaptive Faster R-CNN for Object Detection in the Wild (PDF)
- Chinese Text in the Wild (PDF, Project/Code)
- TSSD: Temporal Single-Shot Detector Based on Attention and LSTM for Robotic Intelligent Perception (PDF)
- Tiny SSD: A Tiny Single-shot Detection Deep Convolutional Neural Network for Real-time Embedded Object Detection (PDF, Reading Note)
- Object Detection in Videos by Short and Long Range Object Linking (PDF)
- Learning a Rotation Invariant Detector with Rotatable Bounding Box (PDF, Project/Code)
- Detecting Curve Text in the Wild: New Dataset and New Solution (PDF, Project/Code)
- Single Shot Text Detector with Regional Attention (PDF, Project/Code)
- Single-Shot Refinement Neural Network for Object Detection (PDF, Project/Code, Reading Note)
- $S^3$FD: Single Shot Scale-invariant Face Detector (PDF, Code/Project, Reading Note)
- MegDet: A Large Mini-Batch Object Detector (PDF)
- Light-Head R-CNN: In Defense of Two-Stage Object Detector (PDF)
- Interpretable R-CNN (PDF)
- Cascade Region Proposal and Global Context for Deep Object Detection (PDF)
- PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection (PDF, Project/Code, Reading Note)
- Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks (PDF, Reading Note)
- Object Detection from Video Tubelets with Convolutional Neural Networks (PDF, Reading Note)
- R-FCN: Object Detection via Region-based Fully Convolutional Networks (PDF, Project/Code, Reading Note)
- SSD: Single Shot MultiBox Detector (PDF, Project/Code, Reading Note)
- Pushing the Limits of Deep CNNs for Pedestrian Detection (PDF, Reading Note)
- Object Detection by Labeling Superpixels(PDF, Reading Note)
- Crafting GBD-Net for Object Detection (PDF, Projct/Code)
code for CUImage and CUVideo, the object detection champion of ImageNet 2016. - Fused DNN: A deep neural network fusion approach to fast and robust pedestrian detection (PDF, Reading Note)
- Training Region-based Object Detectors with Online Hard Example Mining (PDF, Reading Note)
- Detecting People in Artwork with CNNs (PDF, Project/Code)
- Deeply supervised salient object detection with short connections (PDF)
- Learning to detect and localize many objects from few examples (PDF)
- Multi-Scale Saliency Detection using Dictionary Learning (PDF)
- Straight to Shapes: Real-time Detection of Encoded Shapes (PDF)
- Weakly Supervised Cascaded Convolutional Networks (PDF, Reading Note)
- Speed/accuracy trade-offs for modern convolutional object detectors (PDF, Reading Note)
- Object Detection via End-to-End Integration of Aspect Ratio and Context Aware Part-based Models and Fully Convolutional Networks (PDF)
- Feature Pyramid Networks for Object Detection (PDF, Reading Note)
- COCO-Stuff: Thing and Stuff Classes in Context (PDF)
- Finding Tiny Faces (PDF)
- Beyond Skip Connections: Top-Down Modulation for Object Detection (PDF, Reading Note)
- YOLO9000: Better, Faster, Stronger (PDF, Project/Code, Reading Note)
- Quantitative Analysis of Automatic Image Cropping Algorithms: A Dataset and Comparative Study (PDF)
- To Boost or Not to Boost? On the Limits of Boosted Trees for Object Detection (PDF)
- Pixel Objectness (PDF, Project/Code, Reading Note)
- DSSD: Deconvolutional Single Shot Detector (PDF, Reading Note)
- A Fast and Compact Salient Score Regression Network Based on Fully Convolutional Network (PDF)
- Wide-Residual-Inception Networks for Real-time Object Detection (PDF)
- Zoom Out-and-In Network with Recursive Training for Object Proposal (PDF, Project/Code)
- Improving Object Detection with Region Similarity Learning (PDF)
- Tree-Structured Reinforcement Learning for Sequential Object Localization (PDF)
- Weakly Supervised Object Localization Using Things and Stuff Transfer (PDF)
- Unsupervised learning from video to detect foreground objects in single images (PDF)
- A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection (PDF, Project/Code)
- A Learning non-maximum suppression (PDF)
- Real Time Image Saliency for Black Box Classifiers (PDF)
- An Efficient Approach for Object Detection and Tracking of Objects in a Video with Variable Background (PDF)
- RON: Reverse Connection with Objectness Prior Networks for Object Detection (PDF, Project/Code)
- Deformable Part-based Fully Convolutional Network for Object Detection (PDF, Reading Note)
- Recurrent Scale Approximation for Object Detection in CNN (PDF)
- DSOD: Learning Deeply Supervised Object Detectors from Scratch (PDF, Project/Code, Reading Note)
- PPR-FCN: Weakly Supervised Visual Relation Detection via Parallel Pairwise R-FCN (PDF)
- Focal Loss for Dense Object Detection (PDF)
- Learning Uncertain Convolutional Features for Accurate Saliency Detection (PDF)
- Optimizing Region Selection for Weakly Supervised Object Detection (PDF)
- Kill Two Birds With One Stone: Boosting Both Object Detection Accuracy and Speed With adaptive Patch-of-Interest Composition (PDF)
- Flow-Guided Feature Aggregation for Video Object Detection (PDF)
- BlitzNet: A Real-Time Deep Network for Scene Understanding ([PDF]( BlitzNet: A Real-Time Deep Network for Scene Understanding), Project/Code)
- RON: Reverse Connection with Objectness Prior Networks for Object Detection (PDF)
- Soft Proposal Networks for Weakly Supervised Object Localization (PDF, Project/Code)
- Feature-Fused SSD: Fast Detection for Small Objects (PDF)
- Light Cascaded Convolutional Neural Networks for Accurate Player Detection (PDF)
- Personalized Saliency and its Prediction (PDF)
- WeText: Scene Text Detection under Weak Supervision (PDF)
- VPGNet: Vanishing Point Guided Network for Lane and Road Marking Detection and Recognition (PDF, Project/Code)
SEGMENTATION/PARSING
CenterMask: single shot instance segmentation with point representation (PDF)
Background Matting: The World is Your Green Screen (PDF, Project/Code, Github)
Towards Real-Time Automatic Portrait Matting on Mobile Devices (PDF, Project/Code)
Panoptic Feature Pyramid Networks (PDF)
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells (PDF)
Deep Learning for Semantic Segmentation on Minimal Hardware (PDF)
TernausNetV2: Fully Convolutional Network for Instance Segmentation (PDF, Project/Code)
Stacked U-Nets: A No-Frills Approach to Natural Image Segmentation (PDF, Project/Code)
Deep Object Co-Segmentation (PDF)
Fusing Hierarchical Convolutional Features for Human Body Segmentation and Clothing Fashion Classification (PDF)
ShuffleSeg: Real-time Semantic Segmentation Network (PDF)
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation (PDF, Project/Code)
Learning random-walk label propagation for weakly-supervised semantic segmentation (PDF)
Panoptic Segmentation (PDF, Reading Note)
Learning to Segment Every Thing (PDF, Project/Code)
Deep Extreme Cut: From Extreme Points to Object Segmentation (PDF)
Instance-aware Semantic Segmentation via Multi-task Network Cascades (PDF, Project/Code)
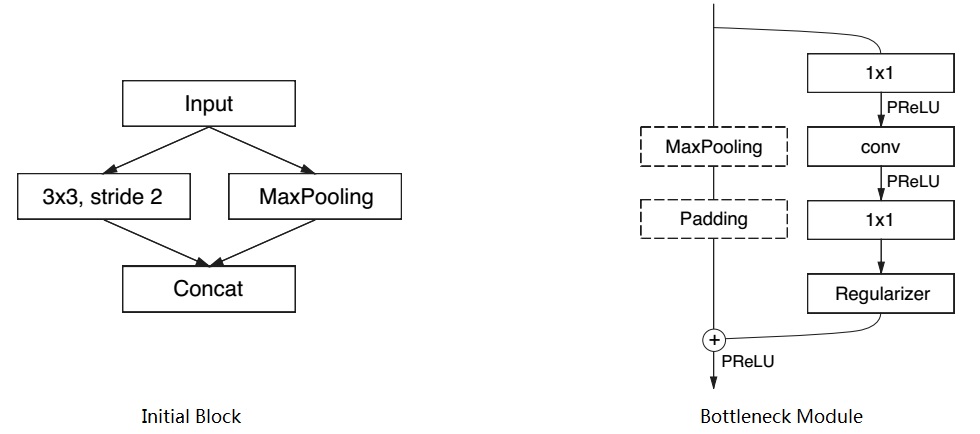
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation (PDF, Reading Note)
Learning Deconvolution Network for Semantic Segmentation (PDF, Reading Note)
Semantic Object Parsing with Graph LSTM (PDF, Reading Note)
Bayesian SegNet: Model Uncertainty in Deep Convolutional Encoder-Decoder Architectures for Scene Understanding (PDF, Reading Note)
Learning to Segment Moving Objects in Videos (PDF, Reading Note)
Deep Structured Features for Semantic Segmentation (PDF)
We propose a highly structured neural network architecture for semantic segmentation of images that combines i) a Haar wavelet-based tree-like convolutional neural network (CNN), ii) a random layer realizing a radial basis function kernel approximation, and iii) a linear classifier. While stages i) and ii) are completely pre-specified, only the linear classifier is learned from data. Thanks to its high degree of structure, our architecture has a very small memory footprint and thus fits onto low-power embedded and mobile platforms. We apply the proposed architecture to outdoor scene and aerial image semantic segmentation and show that the accuracy of our architecture is competitive with conventional pixel classification CNNs. Furthermore, we demonstrate that the proposed architecture is data efficient in the sense of matching the accuracy of pixel classification CNNs when trained on a much smaller data set.
CNN-aware Binary Map for General Semantic Segmentation (PDF)
Learning to Refine Object Segments (PDF)
Clockwork Convnets for Video Semantic Segmentation(PDF, Project/Code)
Convolutional Gated Recurrent Networks for Video Segmentation (PDF)
Efficient Convolutional Neural Network with Binary Quantization Layer (PDF)
One-Shot Video Object Segmentation (PDF)
Fully Convolutional Instance-aware Semantic Segmentation (PDF, Projcet/Code, Reading Note)
Semantic Segmentation using Adversarial Networks (PDF)
Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes (PDF)
Deep Watershed Transform for Instance Segmentation (PDF)
InstanceCut: from Edges to Instances with MultiCut (PDF)
The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation (PDF)
Improving Fully Convolution Network for Semantic Segmentation (PDF)
Video Scene Parsing with Predictive Feature Learning (PDF)
Training Bit Fully Convolutional Network for Fast Semantic Segmentation (PDF)
Pyramid Scene Parsing Network (PDF, Reading Note)
Mining Pixels: Weakly Supervised Semantic Segmentation Using Image Labels (PDF)
FastMask: Segment Object Multi-scale Candidates in One Shot (PDF, Project/Code, Reading Note)
A New Convolutional Network-in-Network Structure and Its Applications in Skin Detection, Semantic Segmentation, and Artifact Reduction (PDF, Reading Note)
FusionSeg: Learning to combine motion and appearance for fully automatic segmention of generic objects in videos (PDF)
Visual Saliency Prediction Using a Mixture of Deep Neural Networks (PDF)
PixelNet: Representation of the pixels, by the pixels, and for the pixels (PDF, Project/Code)
Super-Trajectory for Video Segmentation (PDF)
Understanding Convolution for Semantic Segmentation (PDF, Reading Note)
Adversarial Examples for Semantic Image Segmentation (PDF)
Large Kernel Matters – Improve Semantic Segmentation by Global Convolutional Network (PDF)
Deep Image Matting (PDF, Reading Note)
Mask R-CNN (PDF, Caffe Implementation, TuSimple Implementation on MXNet, TensorFlow Implementation, Reading Note)
Predicting Deeper into the Future of Semantic Segmentation (PDF)
Convolutional Oriented Boundaries: From Image Segmentation to High-Level Tasks (PDF, Project/Code)
One-Shot Video Object Segmentation (PDF, Project/Code)
Semantic Instance Segmentation via Deep Metric Learning (PDF)
Not All Pixels Are Equal: Difficulty-aware Semantic Segmentation via Deep Layer Cascade (PDF)
Semantically-Guided Video Object Segmentation (PDF)
Recurrent Multimodal Interaction for Referring Image Segmentation (PDF)
Loss Max-Pooling for Semantic Image Segmentation (PDF)
Reformulating Level Sets as Deep Recurrent Neural Network Approach to Semantic Segmentation (PDF)
Learning Video Object Segmentation with Visual Memory (PDF)
A Review on Deep Learning Techniques Applied to Semantic Segmentation (PDF)
BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation with Fully Convolutional Networks (PDF)
Rethinking Atrous Convolution for Semantic Image Segmentation (PDF)
Discriminative Localization in CNNs for Weakly-Supervised Segmentation of Pulmonary Nodules (PDF)
Superpixel-based semantic segmentation trained by statistical process control (PDF)
The Devil is in the Decoder (PDF)
Semantic Segmentation with Reverse Attention (PDF)
Learning Deconvolution Network for Semantic Segmentation (PDF, Project/Code)
Depth Adaptive Deep Neural Network for Semantic Segmentation (PDF)
Semantic Instance Segmentation with a Discriminative Loss Function (PDF)
A Cost-Sensitive Visual Question-Answer Framework for Mining a Deep And-OR Object Semantics from Web Images (PDF)
ICNet for Real-Time Semantic Segmentation on High-Resolution Images (PDF, Project/Code)
Pyramid Scene Parsing Network (PDF, Project/Code, Reading Note)
Learning to Segment Instances in Videos with Spatial Propagation Network (PDF, Project/Code)
Learning Affinity via Spatial Propagation Networks (PDF, Project/Code)
TRACKING
- Tracking Objects as Points (PDF, Project/Code)
- Deeper and Wider Siamese Networks for Real-Time Visual Tracking (PDF)
- Multiple People Tracking Using Hierarchical Deep Tracklet Re-identification (PDF)
- Fully-Convolutional Siamese Networks for Object Tracking (PDF)
- Joint Flow: Temporal Flow Fields for Multi Person Tracking (PDF)
- Trajectory Factory: Tracklet Cleaving and Re-connection by Deep Siamese Bi-GRU for Multiple Object Tracking (PDF)
- Machine Learning Methods for Solving Assignment Problems in Multi-Target Tracking (PDF)
- Multi-Target, Multi-Camera Tracking by Hierarchical Clustering: Recent Progress on DukeMTMC Project (PDF)
- Detect-and-Track: Efficient Pose Estimation in Videos (PDF)
- Track, then Decide: Category-Agnostic Vision-based Multi-Object Tracking (PDF)
- Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking (PDF, Reading Note)
- Joint Tracking and Segmentation of Multiple Targets (PDF, Reading Note)
- Deep Tracking on the Move: Learning to Track the World from a Moving Vehicle using Recurrent Neural Networks (PDF)
- Convolutional Regression for Visual Tracking (PDF)
- Kernelized Correlation Filters(Project CODE1 CODE2)
- Online Visual Multi-Object Tracking via Labeled Random Finite Set Filtering (PDF)
- SANet: Structure-Aware Network for Visual Tracking (PDF)
- Semantic tracking: Single-target tracking with inter-supervised convolutional networks (PDF)
- On The Stability of Video Detection and Tracking (PDF)
- Dual Deep Network for Visual Tracking (PDF)
- Deep Motion Features for Visual Tracking (PDF)
- Robust and Real-time Deep Tracking Via Multi-Scale Domain Adaptation (PDF, Project/Code)
- Instance Flow Based Online Multiple Object Tracking (PDF)
- PathTrack: Fast Trajectory Annotation with Path Supervision (PDF)
- Good Features to Correlate for Visual Tracking (PDF)
- Re3 : Real-Time Recurrent Regression Networks for Object Tracking (PDF)
- Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning (PDF, Project/Code)
- Simple Online and Realtime Tracking with a Deep Association Metric (PDF)
- Learning Policies for Adaptive Tracking with Deep Feature Cascades (PDF)
- Recurrent Filter Learning for Visual Tracking (PDF)
- Tracking Persons-of-Interest via Unsupervised Representation Adaptation (PDF)
- Detect to Track and Track to Detect (PDF, Project/Code, Reading Note)
POSE ESTIMATION
- Human Pose Estimation with Spatial Contextual Information (PDF)
- Rethinking on Multi-Stage Networks for Human Pose Estimation (PDF)
- Learning to Estimate 3D Human Pose and Shape from a Single Color Image (PDF, Project/Code)
- Ordinal Depth Supervision for 3D Human Pose Estimation (PDF, Project/Code)
- Simple Baselines for Human Pose Estimation and Tracking (PDF)
- End-to-end Recovery of Human Shape and Pose (PDF, PROJECT/CODE, Code)
- PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model (PDF)
- DensePose: Dense Human Pose Estimation In The Wild (PDF, Project/Code)
- Cascaded Pyramid Network for Multi-Person Pose Estimation (PDF)
- Chained Predictions Using Convolutional Neural Networks (PDF, Reading Note)
- CRF-CNN: Modeling Structured Information in Human Pose Estimation (PDF)
- Convolutional Pose Machines (PDF, Project/Code, Reading Note)
- Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields (PDF, Project/Code, Reading Note)
- Towards Accurate Multi-person Pose Estimation in the Wild (PDF, Reading Note)
- Adversarial PoseNet: A Structure-aware Convolutional Network for Human Pose Estimation (PDF)
- Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose (PDF, Project/Code)
- Learning Feature Pyramids for Human Pose Estimation (PDF, Project/Code)
- Joint Multi-Person Pose Estimation and Semantic Part Segmentation (PDF)
- DeepPrior++: Improving Fast and Accurate 3D Hand Pose Estimation (PDF)
- Lifting from the Deep: Convolutional 3D Pose Estimation from a Single Image (PDF)
- Human Pose Regression by Combining Indirect Part Detection and Contextual Information (PDF)
- Dual Path Networks for Multi-Person Human Pose Estimation (PDF)
ACTION RECOGNITION/EVENT DETECTION/VIDEO
- Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition (PDF, Project/Code)
- CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes (PDF, Project/Code, MxNet Version, Reading Note)
- SlowFast Networks for Video Recognition (PDF)
- PHD-GIFs: Personalized Highlight Detection for Automatic GIF Creation (PDF, Project/Code)
- Superframes, A Temporal Video Segmentation (PDF)
- Co-occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation (PDF)
- 2D/3D Pose Estimation and Action Recognition using Multitask Deep Learning (PDF)
- Real-Time End-to-End Action Detection with Two-Stream Networks (PDF)
- Learning Video-Story Composition via Recurrent Neural Network (PDF)
- Real-world Anomaly Detection in Surveillance Videos (PDF)
- Fully-Coupled Two-Stream Spatiotemporal Networks for Extremely Low Resolution Action Recognition (PDF)
- Deep Reinforcement Learning for Unsupervised Video Summarization with Diversity-Representativeness Reward (PDF, Project/Code)
- Making a long story short: A Multi-Importance Semantic for Fast-Forwarding Egocentric Videos (PDF)
- Attentional Pooling for Action Recognition (PDF, Project/Code)
- Pooling the Convolutional Layers in Deep ConvNets for Action Recognition (PDF, Reading Note)
- Two-Stream Convolutional Networks for Action Recognition in Videos (PDF, Reading Note)
- YouTube-8M: A Large-Scale Video Classification Benchmark (PDF, Project/Code)
- Spatiotemporal Residual Networks for Video Action Recognition (PDF)
- An End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data (PDF)
- Fast Video Classification via Adaptive Cascading of Deep Models (PDF)
- Video Pixel Networks (PDF)
- Plug-and-Play CNN for Crowd Motion Analysis: An Application in Abnormal Event Detection (PDF)
- EM-Based Mixture Models Applied to Video Event Detection (PDF)
- Video Captioning and Retrieval Models with Semantic Attention (PDF)
- Title Generation for User Generated Videos (PDF)
- Review of Action Recognition and Detection Methods (PDF)
- RECURRENT MIXTURE DENSITY NETWORK FOR SPATIOTEMPORAL VISUAL ATTENTION (PDF)
- Self-Supervised Video Representation Learning With Odd-One-Out Networks (PDF)
- Recurrent Memory Addressing for describing videos (PDF)
- Online Real time Multiple Spatiotemporal Action Localisation and Prediction on a Single Platform (PDF)
- Real-Time Video Highlights for Yahoo Esports (PDF)
- Surveillance Video Parsing with Single Frame Supervision (PDF)
- Anomaly Detection in Video Using Predictive Convolutional Long Short-Term Memory Networks (PDF)
- Action Recognition with Dynamic Image Networks (PDF)
- ActionFlowNet: Learning Motion Representation for Action Recognition (PDF)
- Video Propagation Networks (PDF)
- Detecting events and key actors in multi-person videos (PDF)
- A Pursuit of Temporal Accuracy in General Activity Detection (PDF, Reading Note)
- Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos (PDF)
- Deceiving Google’s Cloud Video Intelligence API Built for Summarizing Videos (PDF)
- Incremental Tube Construction for Human Action Detection (PDF)
- Unsupervised Action Proposal Ranking through Proposal Recombination (PDF)
- CERN: Confidence-Energy Recurrent Network for Group Activity Recognition (PDF)
- Forecasting Human Dynamics from Static Images (PDF)
- Interpretable 3D Human Action Analysis with Temporal Convolutional Networks (PDF)
- Training object class detectors with click supervision (PDF)
- Skeleton-based Action Recognition with Convolutional Neural Networks (PDF)
- Online growing neural gas for anomaly detection in changing surveillance scenes (PDF)
- Learning Person Trajectory Representations for Team Activity Analysis (PDF)
- Concurrence-Aware Long Short-Term Sub-Memories for Person-Person Action Recognition (PDF)
- Video Imagination from a Single Image with Transformation Generation (PDF, Project/Code)
- Optimizing Deep CNN-Based Queries over Video Streams at Scale (PDF, Project/Code, Reading Note)
- Extreme Low Resolution Activity Recognition with Multi-Siamese Embedding Learning (PDF)
- Predicting Human Activities Using Stochastic Grammar (PDF)
- Discriminative convolutional Fisher vector network for action recognition (PDF)
- Extreme Low Resolution Activity Recognition with Multi-Siamese Embedding Learning (PDF)
- Exploiting Semantic Contextualization for Interpretation of Human Activity in Videos (PDF)
- Lattice Long Short-Term Memory for Human Action Recognition (PDF)
- Kinship Verification from Videos using Spatio-Temporal Texture Features and Deep Learning (PDF)
- Fast-Forward Video Based on Semantic Extraction (PDF)
- Emotion Detection on TV Show Transcripts with Sequence-based Convolutional Neural Networks (PDF)
- ConvNet Architecture Search for Spatiotemporal Feature Learning (PDF, Project/Code, Github)
- Fully Context-Aware Video Prediction (PDF)
FACE
- BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs (PDF)
- A Dataset and Benchmark for Large-scale Multi-modal Face Anti-spoofing (PDF, Project/Code)
- Learning towards Minimum Hyperspherical Energy (PDF, Project/Code)
- Consensus-Driven Propagation in Massive Unlabeled Data for Face Recognition (PDF, Code/Project)
- Arbitrary Facial Attribute Editing: Only Change What You Want (PDF, Project/Code)
- Anchor Cascade for Efficient Face Detection (PDF)
- Real-Time Rotation-Invariant Face Detection with Progressive Calibration Networks (PDF, Reading Note)
- MobileFaceNets: Efficient CNNs for Accurate Real-time Face Verification on Mobile Devices (PDF)
- Survey of Face Detection on Low-quality Images (PDF)
- PyramidBox: A Context-assisted Single Shot Face Detector (PDF)
- SFace: An Efficient Network for Face Detection in Large Scale Variations ([PDF](SFace: An Efficient Network for Face Detection in Large Scale Variations))
- Deep Facial Expression Recognition: A Survey (PDF)
- Deep Face Recognition: A Survey (PDF)
- Deep Semantic Face Deblurring (PDF, Project/Code)
- Evaluation of Dense 3D Reconstruction from 2D Face Images in the Wild (PDF)
- SSH: Single Stage Headless Face Detector (PDF, Project/Code)
- Detecting and counting tiny faces (PDF, Project/Code)
- Training Deep Face Recognition Systems with Synthetic Data (PDF)
- Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification (PDF, Project/Code)
- Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks (PDF, Project/Code, Code Caffe)
- Deep Architectures for Face Attributes (PDF)
- Face Detection with End-to-End Integration of a ConvNet and a 3D Model (PDF, Reading Note, Project/Code)
- A CNN Cascade for Landmark Guided Semantic Part Segmentation (PDF, Project/Code)
- Kernel Selection using Multiple Kernel Learning and Domain Adaptation in Reproducing Kernel Hilbert Space, for Face Recognition under Surveillance Scenario (PDF)
- An All-In-One Convolutional Neural Network for Face Analysis (PDF)
- Fast Face-swap Using Convolutional Neural Networks (PDF)
- Cross-Age Reference Coding for Age-Invariant Face Recognition and Retrieval (Project/Code)
- CMS-RCNN: Contextual Multi-Scale Region-based CNN for Unconstrained Face Detection (Project/Code)
- Face Synthesis from Facial Identity Features (PDF)
- DeepFace: Face Generation using Deep Learning (PDF)
- Emotion Recognition in the Wild via Convolutional Neural Networks and Mapped Binary Patterns (PDF, Project/Code)
- EmotioNet Challenge: Recognition of facial expressions of emotion in the wild (PDF)
- Unrestricted Facial Geometry Reconstruction Using Image-to-Image Translation (PDF)
- Semi and Weakly Supervised Semantic Segmentation Using Generative Adversarial Network (PDF)
- Deep Alignment Network: A convolutional neural network for robust face alignment (PDF, Project/Code)
- Scale-Aware Face Detection (PDF)
- SSH: Single Stage Headless Face Detector (PDF)
- AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild (PDF)
- SphereFace: Deep Hypersphere Embedding for Face Recognition (PDF, Project/Code)
- Age Group and Gender Estimation in the Wild with Deep RoR Architecture (PDF)
- Island Loss for Learning Discriminative Features in Facial Expression Recognition (PDF)
- Temporal Non-Volume Preserving Approach to Facial Age-Progression and Age-Invariant Face Recognition (PDF)
OPTICAL FLOW
- LiteFlowNet: A Lightweight Convolutional Neural Network for Optical Flow Estimation (PDF, Project/Code)
- DeepFlow: Large displacement optical flow with deep matching (PDF, Project/Code)
- Guided Optical Flow Learning (PDF)
IMAGE PROCESSING
- R2D2: Repeatable and Reliable Detector and Descriptor (PDF)
- CartoonGAN: Generative Adversarial Networks for Photo Cartoonization (PDF)
- Image Inpainting for Irregular Holes Using Partial Convolutions (PDF)
- Neural Aesthetic Image Reviewer (PDF, Reading Note)
- Automatic Image Cropping for Visual Aesthetic Enhancement Using Deep Neural Networks and Cascaded Regression (PDF)
- Learning Intelligent Dialogs for Bounding Box Annotation (PDF)
- Real-time video stabilization and mosaicking for monitoring and surveillance (PDF, Project/Code)
- Learning Recursive Filter for Low-Level Vision via a Hybrid Neural Network (PDF, Project/Code)
- Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding(PDF, Project/Code)
- A Learned Representation For Artistic Style(PDF)
- Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification (PDF, Project/Code)
- Pixel Recurrent Neural Networks (PDF)
- Conditional Image Generation with PixelCNN Decoders (PDF, Project/Code)
- RAISR: Rapid and Accurate Image Super Resolution (PDF)
- Photo-Quality Evaluation based on Computational Aesthetics: Review of Feature Extraction Techniques (PDF)
- Fast color transfer from multiple images (PDF)
- Bringing Impressionism to Life with Neural Style Transfer in Come Swim (PDF)
- PixelCNN++: Improving the PixelCNN with Discretized Logistic Mixture Likelihood and Other Modifications (PDF, (Project/CODE)[https://github.com/openai/pixel-cnn])
- Deep Photo Style Transfer (PDF)
- A Neural Representation of Sketch Drawings (PDF)
- Visual Attribute Transfer through Deep Image Analogy (PDF)
- Deep Semantics-Aware Photo Adjustment (PDF)
- Diversified Texture Synthesis with Feed-forward Networks (PDF, Project/Code)
- Real-Time Neural Style Transfer for Videos (PDF)
- Creatism: A deep-learning photographer capable of creating professional work (PDF)
- Deep Image Harmonization (PDF, Project/Code)
- Neural Color Transfer between Images (PDF)
- Deeper, Broader and Artier Domain Generalization (PDF)
3D/DEPTH/POINT CLOUD
- The Perfect Match: 3D Point Cloud Matching with Smoothed Densities (PDF, Project/Code)
- Pix3D: Dataset and Methods for Single-Image 3D Shape Modeling (PDF, Project/Code)
- Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unknown Cameras (PDF)
CNN AND DEEP LEARNING
ResNeSt: Split-Attention Networks (PDF, Project/Code, Reading Note)
Meta-Learning in Neural Networks: A Survey (PDF, )
Generalizing from a Few Examples: A Survey on Few-Shot Learning (PDF)
NBDT: Neural-Backed Decision Trees (PDF, Project/Code, Github, Reading Note)
Interpretable CNNs (PDF)
Bag of Tricks for Image Classification with Convolutional Neural Networks (PDF)
How Does Batch Normalization Help Optimization? (PDF, VIDEO)
Rethinking ImageNet Pre-training (PDF)
Learning From Positive and Unlabeled Data: A Survey (PDF)
Gather-Excite: Exploiting Feature Context in Convolutional Neural Networks (PDF, Project/Code)
DropBlock: A regularization method for convolutional networks (PDF)
Differentiable Abstract Interpretation for Provably Robust Neural Networks (PDF, Project/Code)
Adding One Neuron Can Eliminate All Bad Local Minima (PDF)
Step Size Matters in Deep Learning (PDF)
Do Better ImageNet Models Transfer Better? (PDF)
Robust Classification with Convolutional Prototype Learning (PDF, Project/Code)
Fast Feature Extraction with CNNs with Pooling Layers (PDF)
Network Transplanting (PDF)
An Information-Theoretic View for Deep Learning (PDF)
Understanding Individual Neuron Importance Using Information Theory (PDF)
Understanding Convolutional Neural Network Training with Information Theory (PDF)
The unreasonable effectiveness of the forget gate (PDF)
Discovering Hidden Factors of Variation in Deep Networks (PDF)
Regularizing Deep Networks by Modeling and Predicting Label Structure (PDF)
Hierarchical Novelty Detection for Visual Object Recognition (PDF)
Guide Me: Interacting with Deep Networks (PDF)
Studying Invariances of Trained Convolutional Neural Networks (PDF)
Deep Residual Networks and Weight Initialization (PDF)
WNGrad: Learn the Learning Rate in Gradient Descent (PDF)
Understanding the Loss Surface of Neural Networks for Binary Classification (PDF)
Tell Me Where to Look: Guided Attention Inference Network (PDF)
Convolutional Neural Networks with Alternately Updated Clique (PDF, Project/Code)
Visual Interpretability for Deep Learning: a Survey (PDF)
Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey (PDF)
CNNs are Globally Optimal Given Multi-Layer Support (PDF)
Take it in your stride: Do we need striding in CNNs? (PDF)
Gradients explode - Deep Networks are shallow - ResNet explained (PDF)
Super-Convergence: Very Fast Training of Residual Networks Using Large Learning Rates (PDF, Project/Code)
Data Distillation: Towards Omni-Supervised Learning (PDF)
Peephole: Predicting Network Performance Before Training (PDF)
AdaBatch: Adaptive Batch Sizes for Training Deep Neural Networks (PDF)
Gradual Tuning: a better way of Fine Tuning the parameters of a Deep Neural Network (PDF)
CondenseNet: An Efficient DenseNet using Learned Group Convolutions (PDF, Project/Code)
Population Based Training of Neural Networks (PDF)
Knowledge Concentration: Learning 100K Object Classifiers in a Single CNN (PDF)
Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions (PDF)
Unleashing the Potential of CNNs for Interpretable Few-Shot Learning (PDF)
Log-DenseNet: How to Sparsify a DenseNet (PDF)
Don’t Decay the Learning Rate, Increase the Batch Size (PDF)
Guarding Against Adversarial Domain Shifts with Counterfactual Regularization (PDF)
UberNet: Training a ‘Universal’ Convolutional Neural Network for Low-, Mid-, and High-Level Vision using Diverse Datasets and Limited Memory (PDF, Project/Code)
What makes ImageNet good for transfer learning? (PDF, Project/Code, Reading Note)
The tremendous success of features learnt using the ImageNet classification task on a wide range of transfer tasks begs the question: what are the intrinsic properties of the ImageNet dataset that are critical for learning good, general-purpose features? This work provides an empirical investigation of various facets of this question: Is more pre-training data always better? How does feature quality depend on the number of training examples per class? Does adding more object classes improve performance? For the same data budget, how should the data be split into classes? Is fine-grained recognition necessary for learning good features? Given the same number of training classes, is it better to have coarse classes or fine-grained classes? Which is better: more classes or more examples per class?
Understanding and Improving Convolutional Neural Networks via Concatenated Rectified Linear Units (PDF)
Densely Connected Convolutional Networks (PDF, Project/Code, Reading Note)
Decoupled Neural Interfaces using Synthetic Gradients (PDF)
Training directed neural networks typically requires forward-propagating data through a computation graph, followed by backpropagating error signal, to produce weight updates. All layers, or more generally, modules, of the network are therefore locked, in the sense that they must wait for the remainder of the network to execute forwards and propagate error backwards before they can be updated. In this work we break this constraint by decoupling modules by introducing a model of the future computation of the network graph. These models predict what the result of the modeled sub-graph will produce using only local information. In particular we focus on modeling error gradients: by using the modeled synthetic gradient in place of true backpropagated error gradients we decouple subgraphs, and can update them independently and asynchronously.
Rethinking the Inception Architecture for Computer Vision (PDF, Reading Note)
In this paper, several network designing choices are discussed, including factorizing convolutions into smaller kernels and asymmetric kernels, utility of auxiliary classifiers and reducing grid size using convolution stride rather than pooling.
Factorized Convolutional Neural Networks (PDF, Reading Note)
Do semantic parts emerge in Convolutional Neural Networks? (PDF, Reading Note)
A Critical Review of Recurrent Neural Networks for Sequence Learning (PDF)
Image Compression with Neural Networks (Project/Code)
Graph Convolutional Networks (Project/Code)
Understanding intermediate layers using linear classifier probes (PDF, Reading Note)
Learning What and Where to Draw (PDF, Project/Code)
On the interplay of network structure and gradient convergence in deep learning (PDF)
Deep Learning with Separable Convolutions (PDF)
Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization (PDF, Project/Code)
Optimization of Convolutional Neural Network using Microcanonical Annealing Algorithm (PDF)
Deep Pyramidal Residual Networks (PDF)
Impatient DNNs - Deep Neural Networks with Dynamic Time Budgets (PDF)
Uncertainty in Deep Learning (PDF, Project/Code)
This is the PhD Thesis of Yarin Gal.Tensorial Mixture Models (PDF, Project/Code)
Multifaceted Feature Visualization: Uncovering the Different Types of Features Learned By Each Neuron in Deep Neural Networks (PDF)
Why Deep Neural Networks? (PDF)
Local Similarity-Aware Deep Feature Embedding (PDF)
A Review of 40 Years of Cognitive Architecture Research: Focus on Perception, Attention, Learning and Applications (PDF)
Professor Forcing: A New Algorithm for Training Recurrent Networks (PDF)
On the expressive power of deep neural networks(PDF)
What Is the Best Practice for CNNs Applied to Visual Instance Retrieval? (PDF)
Deep Convolutional Neural Network Design Patterns (PDF, Project/Code)
Tricks from Deep Learning (PDF)
A Connection between Generative Adversarial Networks, Inverse Reinforcement Learning, and Energy-Based Models (PDF)
Multi-Shot Mining Semantic Part Concepts in CNNs (PDF)
Aggregated Residual Transformations for Deep Neural Networks (PDF, Reading Note)
PolyNet: A Pursuit of Structural Diversity in Very Deep Networks (PDF)
On the Exploration of Convolutional Fusion Networks for Visual Recognition (PDF)
ResFeats: Residual Network Based Features for Image Classification (PDF)
Object Recognition with and without Objects (PDF)
LCNN: Lookup-based Convolutional Neural Network (PDF, Reading Note)
Inductive Bias of Deep Convolutional Networks through Pooling Geometry (PDF, Project/Code)
Wider or Deeper: Revisiting the ResNet Model for Visual Recognition (PDF, Reading Note)
Multi-Scale Context Aggregation by Dilated Convolutions (PDF, Project/Code)
Large-Margin Softmax Loss for Convolutional Neural Networks (PDF, mxnet Code, Caffe Code)
Adversarial Examples Detection in Deep Networks with Convolutional Filter Statistics (PDF)
Feedback Networks (PDF)
Visualizing Residual Networks (PDF)
Convolutional Oriented Boundaries: From Image Segmentation to High-Level Tasks (PDF, Project/Code)
Understanding trained CNNs by indexing neuron selectivity (PDF)
Benchmarking State-of-the-Art Deep Learning Software Tools (PDF, Project/Code)
Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-Normalized Models (PDF)
Visualizing Deep Neural Network Decisions: Prediction Difference Analysis (PDF, Project/Code)
ShaResNet: reducing residual network parameter number by sharing weights (PDF)
Deep Forest: Towards An Alternative to Deep Neural Networks (PDF, Project/Code)
All You Need is Beyond a Good Init: Exploring Better Solution for Training Extremely Deep Convolutional Neural Networks with Orthonormality and Modulation (PDF)
Genetic CNN (PDF)
Deformable Convolutional Networks (PDF)
Quality Resilient Deep Neural Networks (PDF)
How ConvNets model Non-linear Transformations (PDF)
Active Convolution: Learning the Shape of Convolution for Image Classification (PDF)
Multi-Scale Dense Convolutional Networks for Efficient Prediction (PDF, Project/Code)
Coordinating Filters for Faster Deep Neural Networks (PDF, Project/Code)
A Genetic Programming Approach to Designing Convolutional Neural Network Architectures (PDF)
On Generalization and Regularization in Deep Learning (PDF)
Interpretable Explanations of Black Boxes by Meaningful Perturbation (PDF)
Energy Propagation in Deep Convolutional Neural Networks (PDF)
Introspection: Accelerating Neural Network Training By Learning Weight Evolution (PDF)
Deeply-Supervised Nets (PDF)
Speeding up Convolutional Neural Networks By Exploiting the Sparsity of Rectifier Units (PDF)
Inception Recurrent Convolutional Neural Network for Object Recognition (PDF)
Residual Attention Network for Image Classification (PDF)
The Landscape of Deep Learning Algorithms (PDF)
Pixel Deconvolutional Networks (PDF)
Dilated Residual Networks (PDF)
A Kernel Redundancy Removing Policy for Convolutional Neural Network (PDF)
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour (PDF)
Learning Spatial Regularization with Image-level Supervisions for Multi-label Image Classification (PDF, Project/Code, Reading Note)
VisualBackProp: efficient visualization of CNNs (PDF)
Pruning Convolutional Neural Networks for Resource Efficient Inference (PDF, Project/Code)
Zero-Shot Learning - A Comprehensive Evaluation of the Good, the Bad and the Ugly (PDF, Project/Code)
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices (PDF, Caffe Implementation)
Submanifold Sparse Convolutional Networks (PDF, Project/Code)
Dual Path Networks (PDF)
ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression (PDF, Project/Code, Reading Note)
Memory-Efficient Implementation of DenseNets (PDF)
Residual Attention Network for Image Classification (PDF, Project/Code)
An Effective Training Method For Deep Convolutional Neural Network (PDF)
Learning to Transfer (PDF)
Learning Efficient Convolutional Networks through Network Slimming (PDF, Project/Code)
Super-Convergence: Very Fast Training of Residual Networks Using Large Learning Rates (PDF, Project/Code)
Hierarchical loss for classification (PDF)
Convolutional Gaussian Processes (PDF, Code/Project)
Interpretable Convolutional Neural Networks (PDF)
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? (PDF)
Porcupine Neural Networks: (Almost) All Local Optima are Global (PDF)
Generalization in Deep Learning (PDF)
A systematic study of the class imbalance problem in convolutional neural networks (PDF)
Interpretable Transformations with Encoder-Decoder Networks (PDF, Project/Code)
One pixel attack for fooling deep neural networks (PDF)
SINGLE-SHOT/UNSUPERVISED LEARNING
- Zero-Shot Object Detection by Hybrid Region Embedding (PDF, Project/Code)
- Deep Triplet Ranking Networks for One-Shot Recognition (PDF)
- Avatar-Net: Multi-scale Zero-shot Style Transfer by Feature Decoration (PDF)
GAN
- A Survey on GANs for Anomaly Detection (PDF)
- Outfit Generation and Style Extraction via Bidirectional LSTM and Autoencoder (PDF)
- Pioneer Networks: Progressively Growing Generative Autoencoder (PDF)
- Transferring GANs: generating images from limited data (PDF, Project/Code)
- Painting Generation Using Conditional Generative Adversarial Net (PDF, Project/Code)
- MGGAN: Solving Mode Collapse using Manifold Guided Training (PDF)
- Multimodal Unsupervised Image-to-Image Translation (PDF, Project/Code)
- Pedestrian-Synthesis-GAN: Generating Pedestrian Data in Real Scene and Beyond (PDF)
- Face Aging with Contextual Generative Adversarial Nets (PDF, Project/Code)
- Deformable GANs for Pose-based Human Image Generation (PDF, Project/Code)
- ComboGAN: Unrestrained Scalability for Image Domain Translation (PDF, Project/Code)
- Eye In-Painting with Exemplar Generative Adversarial Networks (PDF)
- Disentangled Person Image Generation (PDF)
- Fader Networks: Manipulating Images by Sliding Attributes (PDF, Code/Project)
- Are GANs Created Equal? A Large-Scale Study (PDF)
- StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation (PDF, Project/Code)
- Two Birds with One Stone: Iteratively Learn Facial Attributes with GANs (PDF, Project/Code)
- Spectral Normalization for Generative Adversarial Networks (PDF)
- XGAN: Unsupervised Image-to-Image Translation for many-to-many Mappings (PDF)
- How Generative Adversarial Nets and its variants Work: An Overview of GAN (PDF)
- DNA-GAN: Learning Disentangled Representations from Multi-Attribute Images (PDF, Project/Code)
- Sobolev GAN (PDF)
- Data Augmentation Generative Adversarial Networks (PDF)
- Conditional Autoencoders with Adversarial Information Factorization (PDF, Project/Code)
- Progressive Growing of GANs for Improved Quality, Stability, and Variation (PDF, Project/Code, Torch, PyTorch, Reading Note)
- Bayesian GAN (PDF, Project/Code)
- Metric Learning-based Generative Adversarial Network (PDF)
- Flexible Prior Distributions for Deep Generative Models (PDF)
- Data Augmentation in Classification using GAN (PDF)
- Semantically Decomposing the Latent Spaces of Generative Adversarial Networks (PDF)
- Multi-View Data Generation Without View Supervision (PDF)
- StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks (PDF)
- Generative Adversarial Networks (PDF)
- Stacked Generative Adversarial Networks (PDF)
- Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks (PDF)
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks (PDF)
- Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks (PDF)
- NIPS 2016 Tutorial: Generative Adversarial Networks (PDF)
- Wasserstein GAN (PDF)
- Adversarial Discriminative Domain Adaptation (PDF, Reading Note)
- Generative Adversarial Nets with Labeled Data by Activation Maximization (PDF)
- Triple Generative Adversarial Nets (PDF)
- On the Quantative Evaluation of Deep Generative Models (PDF)
- Adversarial Transformation Networks: Learning to Generate Adversarial Examples (PDF)
- Improved Training of Wasserstein GANs (PDF, Project/Code)
- Generate To Adapt: Aligning Domains using Generative Adversarial Networks (PDF)
- Adversarial Generator-Encoder Networks (PDF, Project/Code)
- Training Triplet Networks with GAN (PDF)
- Multi-Agent Diverse Generative Adversarial Networks (PDF)
- GP-GAN: Towards Realistic High-Resolution Image Blending (PDF, Project/Code)
- BEGAN: Boundary Equilibrium Generative Adversarial Networks (PDF)
- MAGAN: Margin Adaptation for Generative Adversarial Networks (PDF)
- Pose Guided Person Image Generation (PDF)
- On the Effects of Batch and Weight Normalization in Generative Adversarial Networks (PDF, Project/Code)
- Aesthetic-Driven Image Enhancement by Adversarial Learning (PDF)
- VEEGAN: Reducing Mode Collapse in GANs using Implicit Variational Learning (PDF, Project/Code
- MoCoGAN: Decomposing Motion and Content for Video Generation (PDF, Project/Code)
- Generative Adversarial Networks: An Overview ((PDF)[https://arxiv.org/abs/1710.07035])
- SalGAN: Visual Saliency Prediction with Generative Adversarial Networks (PDF, Project/Code)
MACHINE LEARNING
- Metric Learning with Adaptive Density Discrimination (PDF, PyTorch, TF)
- Accelerated Gradient Descent Escapes Saddle Points Faster than Gradient Descent (PDF)
- 计算机视觉与机器学习 【随机森林】
- 计算机视觉与机器学习 【深度学习中的激活函数】
- 我爱机器学习 机器学习干货站
- Bayesian Reasoning and Machine Learning
- Stochastic Gradient Descent as Approximate Bayesian Inference (PDF)
LIGHT-WEIGHT MODEL/EMBEDDED/MOBILE/MODEL COMPRESSION
- MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning (PDF, Project/Code)
- PyTorch Network Slimming (PDF, Project/Code)
- Importance Estimation for Neural Network Pruning (PDF, Project/Code)
- MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning (PDF)
- EFFICIENT METHODS AND HARDWARE FOR DEEP LEARNING (PDF)
- ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware (PDF, Project/Code)
- FD-MobileNet: Improved MobileNet with a Fast Downsampling Strategy (PDF)
- Quantization Mimic: Towards Very Tiny CNN for Object Detection (PDF)
- Pelee: A Real-Time Object Detection System on Mobile Devices (PDF, Project/Code, TensorRT Implemented, Reading Note)
- MobileNetV2: Inverted Residuals and Linear Bottlenecks (PDF, Reading Note)
- SBNet: Sparse Blocks Network for Fast Inference (PDF, Project/Code)
- IGCV2: Interleaved Structured Sparse Convolutional Neural Networks (PDF)
- FitNets: Hints for Thin Deep Nets (PDF)
- Building Efficient ConvNets using Redundant Feature Pruning (PDF, Project/Code)
- Multi-Scale Dense Networks for Resource Efficient Image Classification (PDF)
- Net-Trim: Convex Pruning of Deep Neural Networks with Performance Guarantee (pdf)
- NISP: Pruning Networks using Neuron Importance Score Propagation (PDF)
- Caffeinated FPGAs: FPGA Framework For Convolutional Neural Networks (PDF)
- Comprehensive Evaluation of OpenCL-based Convolutional Neural Network Accelerators in Xilinx and Altera FPGAs (PDF)
- FINN: A Framework for Fast, Scalable Binarized Neural Network Inference (PDF)
- Two-Bit Networks for Deep Learning on Resource-Constrained Embedded Devices (PDF)
- SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size (PDF, Project/Code)
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (PDF, Caffe Implementation, Reading Note)
- Binarized Convolutional Neural Networks with Separable Filters for Efficient Hardware Acceleration (PDF)
- Channel Pruning for Accelerating Very Deep Neural Networks (PDF, Project/Code)
- Quantized Convolutional Neural Networks for Mobile Devices (PDF, Project/Code)
- Squeeze-and-Excitation Networks (PDF)
- Domain-adaptive deep network compression (PDF)
- Embedded Binarized Neural Networks (PDF)
- Keynote: Small Neural Nets Are Beautiful: Enabling Embedded Systems with Small Deep-Neural-Network Architectures (PDF)
- A Survey of Model Compression and Acceleration for Deep Neural Networks ([https://arxiv.org/abs/1710.09282])
ReID
- Video-based Person Re-identification via 3D Convolutional Networks and Non-local Attention (PDF)
- Attention-Aware Compositional Network for Person Re-identification (PDF)
- Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-identification (PDF, Project/Code)
- Features for Multi-Target Multi-Camera Tracking and Re-Identification (PDF)
- Video Person Re-identification by Temporal Residual Learning (PDF)
- Harmonious Attention Network for Person Re-Identification (PDF)
- In Defense of the Triplet Loss for Person Re-Identification (PDF)
- Deep Spatial Feature Reconstruction for Partial Person Re-identification: Alignment-Free Approach (PDF)
- AlignedReID: Surpassing Human-Level Performance in Person Re-Identification (PDF)
- A Discriminatively Learned CNN Embedding for Person Re-identification (PDF, Project/Code)
- Learning Deep Neural Networks for Vehicle Re-ID with Visual-spatio-temporal Path Proposals (PDF)
- Beyond triplet loss: a deep quadruplet network for person re-identification (PDF)
- Person Re-identification by Local Maximal Occurrence Representation and Metric Learning (PDF, Project/Code)
- Person Re-identification: Past, Present and Future (PDF)
- Unsupervised Person Re-identification: Clustering and Fine-tuning (PDF, Project/Code)
- Jointly Attentive Spatial-Temporal Pooling Networks for Video-based Person Re-Identification (PDF)
- Divide and Fuse: A Re-ranking Approach for Person Re-identification (PDF)
- Learning Deep Context-aware Features over Body and Latent Parts for Person Re-identification (PDF)
- HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis (PDF, Project/Code)
FASHION
- Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba (PDF)
- Visually-Aware Fashion Recommendation and Design with Generative Image Models ([PDF](Visually-Aware Fashion Recommendation and Design with Generative Image Models))
- Be Your Own Prada: Fashion Synthesis with Structural Coherence (PDF, Project/Code, Reading Note)
- Style2Vec: Representation Learning for Fashion Items from Style Sets (PDF)
- Dress like a Star: Retrieving Fashion Products from Videos (PDF)
- The Conditional Analogy GAN: Swapping Fashion Articles on People Images (PDF)
OTHER
- GaitSet: Regarding Gait as a Set for Cross-View Gait Recognition (PDF, Project/Code)
- Deep Clustering for Unsupervised Learning of Visual Features (PDF)
- Detecting Visual Relationships Using Box Attention (PDF)
- Zoom-Net: Mining Deep Feature Interactions for Visual Relationship Recognition (PDF, Project/Code)
- Learning to See in the Dark(PDF)
- A Variational U-Net for Conditional Appearance and Shape Generation (PDF, Project/Code)
- Synthesizing Images of Humans in Unseen Poses (PDF)
- End-to-end weakly-supervised semantic alignment (PDF, Project/Code)
- Dense Optical Flow based Change Detection Network Robust to Difference of Camera Viewpoints (PDF)
- Dual-Path Convolutional Image-Text Embedding (PDF, Project/Code)
- The Promise and Peril of Human Evaluation for Model Interpretability (PDF)
- Semantic Image Retrieval via Active Grounding of Visual Situations (PDF)
- LIFT: Learned Invariant Feature Transform (PDF)
- Learning Aligned Cross-Modal Representations from Weakly Aligned Data (PDF, Project/Code)
- Multi-Task Curriculum Transfer Deep Learning of Clothing Attributes (PDF)
- End-to-end Learning of Deep Visual Representations for Image Retrieval (PDF)
- SoundNet: Learning Sound Representations from Unlabeled Video (PDF)
- Bags of Local Convolutional Features for Scalable Instance Search (PDF, Project/Code)
- Universal Correspondence Network (PDF, Project/Code)
- Judging a Book By its Cover (PDF)
- Generalisation and Sharing in Triplet Convnets for Sketch based Visual Search (PDF)
- Analysis and Optimization of Loss Functions for Multiclass, Top-k, and Multilabel Classification (PDF)
- Automatic generation of large-scale handwriting fonts via style learning (PDF)
- Image Retrieval with Deep Local Features and Attention-based Keypoints (PDF)
- Visual Discovery at Pinterest (PDF)
- Learning to Detect Human-Object Interactions (PDF, Project/Code, Reading Note)
- Learning Deep Features via Congenerous Cosine Loss for Person Recognition (PDF)
- Large-Scale Evolution of Image Classifiers (PDF)
- Deep Variation-structured Reinforcement Learning for Visual Relationship and Attribute Detection (PDF)
- Twitter100k: A Real-world Dataset for Weakly Supervised Cross-Media Retrieval (PDF, Project/Code)
- Mixture of Counting CNNs: Adaptive Integration of CNNs Specialized to Specific Appearance for Crowd Counting (PDF)
- Computer Vision for Autonomous Vehicles: Problems, Datasets and State-of-the-Art (PDF, Project/Code)
- Learning Features by Watching Objects Move (PDF, Project/Code)
- GMS: Grid-based Motion Statistics for Fast, Ultra-robust Feature Correspondence (PDF, Project/Code)
- ResnetCrowd: A Residual Deep Learning Architecture for Crowd Counting, Violent Behaviour Detection and Crowd Density Level Classification (PDF)
- Learning Cross-modal Embeddings for Cooking Recipes and Food Images (PDF, Project/Code)
- Convolutional neural network architecture for geometric matching (PDF, Project/Code)
- Semantic Compositional Networks for Visual Captioning (PDF, Project/Code)
- CNN-based Cascaded Multi-task Learning of High-level Prior and Density Estimation for Crowd Counting (PDF)
- Understanding Black-box Predictions via Influence Functions (PDF)
- Learning a Repression Network for Precise Vehicle Search (PDF)
- Visual Graph Mining (PDF)
- A Deep Multimodal Approach for Cold-start Music Recommendation (PDF)
- A Multilayer-Based Framework for Online Background Subtraction with Freely Moving Cameras (PDF)
- A self-organizing neural network architecture for learning human-object interactions (PDF)
INTERESTING FINDS
RESOURCES/PERSPECTIVES
- Polylidar
- Network-acceleration
- Awesome-Skeleton-based-Action-Recognition
- AI at the edge A curated list of hardware, software, frameworks and other resources for Artificial Intelligence at the edge. Inspired by awesome-dataviz.
- Ultra-Light-Fast-Generic-Face-Detector-1MB 超轻量级通用人脸检测模型
- Towards-Realtime-MOT Joint Detection and Embedding for fast multi-object tracking
- RFSong-7993 设计的轻量级 RFB 进行行人检测,AP 达到 0.7993,参数量仅有 3.1MB,200 FPS
- Awesome Computer Vision Models This is the list with popular classification and segmentation models related with corresponding evaluation metrics.
- Real-time network for mobile devices real-time network architecture for mobile devices and semantic segmentation
- The Art of C++ A collection of high-quality C++ libraries
- Reinforcement Learning Algorithms Implementation of Reinforcement Learning Algorithms. Python, OpenAI Gym, Tensorflow. Exercises and Solutions to accompany Sutton’s Book and David Silver’s course.
- Generative Deep Learning Generative modeling is one of the hottest topics in AI. It’s now possible to teach a machine to excel at human endeavors such as painting, writing, and composing music. With this practical book, machine-learning engineers and data scientists will discover how to re-create some of the most impressive examples of generative deep learning models, such as variational autoencoders,generative adversarial networks (GANs), encoder-decoder models and world models.
- High Performance Face Recognition This repository provides several high performance models for unconstrained / large-scale / low-shot face recognition.
- Awesome-Trajectory-Prediction This is a list of useful information about trajectory prediction. Related papers, datasets and codes are included.
- Pedestrian Attribute Recognition Paper List
- PlotNeuralNet Latex code for making neural networks diagrams
- Build your own x
- PyTorch Exercise Codes for Deep Learning Researchers
- Python Regular Expressions Cheat Sheet
- PyTorch-GAN
PyTorch implementations of Generative Adversarial Networks. - A Gentle Introduction to Transfer Learning for Image Classification
- GAN Timeline
A timeline showing the development of Generative Adversarial Networks (GAN). - arXiv(Computer Vision and Pattern Recognition)
A good place to explore latest papers. - Awesome Dataset Tools
A curated list of awesome dataset tools - Awesome Computer Vision
A curated list of awesome computer vision resources. - Awesome Deep Vision
A curated list of deep learning resources for computer vision. - Awesome MXNet
This page contains a curated list of awesome MXnet examples, tutorials and blogs. - Awesome TensorFlow
A curated list of awesome TensorFlow experiments, libraries, and projects. - gans-awesome-applications
Curated list of awesome GAN applications and demonstrations. - Deep Reinforcement Learning survey
This paper list is a bit different from others. The author puts some opinion and summary on it. However, to understand the whole paper, you still have to read it by yourself! - TensorFlow 官方文档中文版
- TensorTalk
A place to find latest work’s codes. - OTB Results
Object tracking benchmark - Adversarial Nets Papers
- Creating Human-Level AI
- cv-tricks.com
- Find deep learning models for your mobile platform
- ICCV 2017 Open Access Repository
PROJECTS
Knowledge-Distillation-Zoo Pytorch implementation of various Knowledge Distillation methods.
mxnet-insightface-cpp This project implement an easy deployable face recognition pipeline with mxnet c++ framework.
Real-Time ArcFace Multiplex Recognition Face Detection and Recognition using RetinaFace and ArcFace, can reach nearly 24 fps at GTX1660ti.
vtkplotter A python module for scientific visualization, analysis and animation of 3D objects and point clouds based on VTK and numpy.
pptk The Point Processing Toolkit (pptk) is a Python package for visualizing and processing 2-d/3-d point clouds.
ffmpeg-cpp A clean C++ wrapper around the ffmpeg libraries.
Human Pose Estimation 101 Basics of 2D and 3D Human Pose Estimation.
Video Classification builds a quick and simple code for video classification (or action recognition) using UCF101 with PyTorch.
RetinaFace-Cpp RetinaFace detector with C++
TensorStream is a C++ library for real-time video stream (e.g. RTMP) decoding to CUDA memory
Neural Network Distiller
Distiller is an open-source Python package for neural network compression research.Neural Network Tools: Converter, Constructor and Analyser
For caffe, pytorch, tensorflow, draknet and so on.TensorFlow Examples
TensorFlow Tutorial with popular machine learning algorithms implementation. This tutorial was designed for easily diving into TensorFlow, through examples.It is suitable for beginners who want to find clear and concise examples about TensorFlow. For readability, the tutorial includes both notebook and code with explanations.TensorFlow Tutorials
These tutorials are intended for beginners in Deep Learning and TensorFlow. Each tutorial covers a single topic. The source-code is well-documented. There is a YouTube video for each tutorial.Deep Learning algorithms with TensorFlow
This repository is a collection of various Deep Learning algorithms implemented using the TensorFlow library. This package is intended as a command line utility you can use to quickly train and evaluate popular Deep Learning models and maybe use them as benchmark/baseline in comparison to your custom models/datasets.TensorLayer
TensorLayer is designed to use by both Researchers and Engineers, it is a transparent library built on the top of Google TensorFlow. It is designed to provide a higher-level API to TensorFlow in order to speed-up experimentations and developments. TensorLayer is easy to be extended and modified. In addition, we provide many examples and tutorials to help you to go through deep learning and reinforcement learning.Easily Create High Quality Object Detectors with Deep Learning
Using dlib to train a CNN to detect.Command Line Neural Network
Neuralcli provides a simple command line interface to a python implementation of a simple classification neural network. Neuralcli allows a quick way and easy to get instant feedback on a hypothesis or to play around with one of the most popular concepts in machine learning today.LSTM for Human Activity Recognition
Human activity recognition using smartphones dataset and an LSTM RNN. The project is based on Tesorflow. A MXNet implementation is MXNET-Scala Human Activity Recognition.YOLO in caffe
This is a caffe implementation of the YOLO:Real-Time Object Detection.MTCNN face detection and alignment in MXNet
This is a python/mxnet implementation of Zhang’s work .Magenta
Magenta is a project from the Google Brain team that asks: Can we use machine learning to create compelling art and music? If so, how? If not, why not?Adversarial Nets Papers
The classical Papers about adversarial netsMushreco
Make a photo of a mushroom and see which species it is. Determine over 200 different species.Neural Enhance
The neural network is hallucinating details based on its training from example images. It’s not reconstructing your photo exactly as it would have been if it was HD. That’s only possible in Hollywood — but using deep learning as “Creative AI” works and it is just as cool!CNN Models by CVGJ
This repository contains convolutional neural network (CNN) models trained on ImageNet by Marcel Simon at the Computer Vision Group Jena (CVGJ) using the Caffe framework. Each model is in a separate subfolder and contains everything needed to reproduce the results. This repository focuses currently contains the batch-normalization-variants of AlexNet and VGG19 as well as the training code for Residual Networks (Resnet).-
YOLOv2 uses a few tricks to improve training and increase performance. Like Overfeat and SSD we use a fully-convolutional model, but we still train on whole images, not hard negatives. Like Faster R-CNN we adjust priors on bounding boxes instead of predicting the width and height outright. However, we still predict the x and y coordinates directly. The full details are in our paper soon to be released on Arxiv, stay tuned!
Lightened CNN for Deep Face Representation
The Deep Face Representation Experiment is based on Convolution Neural Network to learn a robust feature for face verification task.-
Open single and half precision gemm implementations. The main speedups over cublas are with small minibatch and in fp16 data formats.
-
style transfer with mxnet
-
This repository contains the source code for cleverhans , a Python library to benchmark machine learning systems’ vulnerability to adversarial examples.
A deep learning traffic light detector using dlib and a few images from Google street view
Deep Video Analytics
Deep Video Analytics provides a platform for indexing and extracting information from videos and images. Deep learning detection and recognition algorithms are used for indexing individual frames / images along with detected objects. The goal of Deep Video analytics is to become a quickly customizable platform for developing visual & video analytics applications, while benefiting from seamless integration with state or the art models released by the vision research community.Yolo_mark
Windows GUI for marking bounded boxes of objects in images for training Yolo v2Yolo-Windows v2 - Windows version of Yolo Convolutional Neural Networks
An Unsupervised Distance Learning Framework for Multimedia Retrieva
Mini Caffe
Minimal runtime core of Caffe, Forward only, GPU support and Memory efficiency.Picasso: A free open-source visualizer for Convolutional Neural Networks
Picasso is a free open-source (Eclipse Public License) DNN visualization tool that gives you partial occlusion and saliency maps with minimal fuss.pix2code: Generating Code from a Graphical User Interface Screenshot
MTCNN-light
this repository is the implementation of MTCNN with no framework, Just need opencv and openblas. “Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Neural Networks”, implemented with C++,no frameworkMobileNet-MXNet
This is a MXNet implementation of Google’s MobileNets.
NEWS/BLOGS
Lil’Log A very informative blog.
A Comprehensive Hands-on Guide to Transfer Learning with Real-World Applications in Deep Learning
Intel’s Neural Compute Stick 2 is 8 times faster than its predecessor
Why is it hard to train deep neural networks? Degeneracy, not vanishing gradients, is the key
ResNet, AlexNet, VGG, Inception: Understanding various architectures of Convolutional Networks
MIT Technology Review
A good place to keep up the trends.LAB41
Lab41 is a Silicon Valley challenge lab where experts from the U.S. Intelligence Community (IC), academia, industry, and In-Q-Tel come together to gain a better understanding of how to work with — and ultimately use — big data.Partnership on AI
Amazon, DeepMind/Google, Facebook, IBM, and Microsoft announced that they will create a non-profit organization that will work to advance public understanding of artificial intelligence technologies (AI) and formulate best practices on the challenges and opportunities within the field. Academics, non-profits, and specialists in policy and ethics will be invited to join the Board of the organization, named the Partnership on Artificial Intelligence to Benefit People and Society (Partnership on AI).爱可可-爱生活 老师的推荐十分值得一看
A Return to Machine Learning
This post is aimed at artists and other creative people who are interested in a survey of recent developments in machine learning research that intersect with art and culture. If you’ve been following ML research recently, you might find some of the experiments interesting but will want to skip most of the explanations.ResNets, HighwayNets, and DenseNets, Oh My!
This post walks through the logic behind three recent deep learning architectures: ResNet, HighwayNet, and DenseNet. Each make it more possible to successfully trainable deep networks by overcoming the limitations of traditional network design.How to build a robot that “sees” with $100 and TensorFlow >I wanted to build a robot that could recognize objects. Years of experience building computer programs and doing test-driven development have turned me into a menace working on physical projects. In the real world, testing your buggy device can burn down your house, or at least fry your motor and force you to wait a couple of days for replacement parts to arrive.
Navigating the unsupervised learning landscape
Unsupervised learning is the Holy Grail of Deep Learning. The goal of unsupervised learning is to create general systems that can be trained with little data. Very little data.Facial Recognition on a Jetson TX1 in Tensorflow
Here’s a way to hack facial recognition system together in relatively short time on NVIDIA’s Jetson TX1.Deep Learning with Generative and Generative Adverserial Networks – ICLR 2017 Discoveries
This blog post gives an overview of Deep Learning with Generative and Adverserial Networks related papers submitted to ICLR 2017.Unsupervised Deep Learning – ICLR 2017 Discoveries
This blog post gives an overview of papers related to Unsupervised Deep Learning submitted to ICLR 2017.Algorithmia will help you make your own AI-powered photo filters
Deep Learning Enables You to Hide Screen when Your Boss is Approaching
How to Train a GAN? Tips and tricks to make GANs work
While research in Generative Adversarial Networks (GANs) continues to improve the fundamental stability of these models, we use a bunch of tricks to train them and make them stable day to day.
Highlights of IEEE Big Data 2016: Nearest Neighbours, Outliers and Deep Learning
Some CNN visualization tools and techniques
Besides this post, the others written by the author are also worthy of reading.Understanding, generalisation, and transfer learning in deep neural networks
NVIDIA Announces The Jetson TX2, Powered By NVIDIA’s “Denver 2” CPU & Pascal Graphics
Can FPGAs Beat GPUs in Accelerating Next-Generation Deep Learning?
Eye Fidelity: How Deep Learning Will Help Your Smartphone Track Your Gaze
Rules of Machine Learning: Best Practices for ML Engineering
A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN
Generative Adversarial Networks (GANs): Engine and Applications
BENCHMARK/LEADERBOARD/DATASET
- AI Benchmark: All About Deep Learning on Smartphones in 2019
- LVIS API LVIS: is a new dataset for Large Vocabulary Instance Segmentation.
- VERI-Wild A Large-Scale Dataset for Vehicle Re-Identification in the Wild
- VeRi dataset is a large scale image dataset for vehicle re-identification in urban traffic surveillance.
- State of the Art
- STAIR Actions: A Video Dataset of Everyday Home Actions
STAIR Actions is a video dataset consisting of 100 everyday human action categories. - Revisiting Oxford and Paris: Large-Scale Image Retrieval Benchmarking
- EPIC-Kitchens
The largest dataset in first-person (egocentric) vision; multi-faceted non-scripted recordings in native environments - i.e. the wearers’ homes, capturing all daily activities in the kitchen over multiple days. Annotations are collected using a novel `live’ audio commentary approach. - Large-Scale Landmark Recognition: A Challenge
- Low-Power Image Recognition Challenge
- Open Images Dataset
Open Images is a dataset of ~9 million URLs to images that have been annotated with image-level labels and bounding boxes spanning thousands of classes. - Visual Tracker Benchmark
This website contains data and code of the benchmark evaluation of online visual tracking algorithms. Join visual-tracking Google groups for further updates, discussions, or QnAs. - Multiple Object Tracking Benchmark
With this benchmark we would like to pave the way for a unified framework towards more meaningful quantification of multi-target tracking. - Leaderboards for the Evaluations on PASCAL VOC Data
- Open Images dataset
Open Images is a dataset of ~9 million URLs to images that have been annotated with labels spanning over 6000 categories. - Open Sourcing 223GB of Driving Data
223GB of image frames and log data from 70 minutes of driving in Mountain View on two separate days, with one day being sunny, and the other overcast. - MS COCO
- UMDFaces Dataset
UMDFaces is a face dataset which has 367,920 faces of 8,501 subjects. From this page you can download the entire dataset and the trained model for predicting the localization of the 21 keypoints. - VideoNet
VideoNet is a new initiative to bring together the community of researchers that have put effort into creating benchmarks for video tasks. - YouTube-BoundingBoxes: A Large High-Precision Human-Annotated Data Set for Object Detection in Video
- KITTI Vision Benchmark Suite
- Duke: A New Large-scale Person Re-identification Dataset derived from DukeMTMC
Duke is a subset of the DukeMTMC for image-based re-ID, in the format of the Market-1501 dataset. The original dataset contains 85-minute high-resolution videos from 8 different cameras. Hand-drawn pedestrain bounding boxes are available. - Releasing the World’s Largest Street-level Imagery Dataset for Teaching Machines to See >Today we present the Mapillary Vistas Dataset—the world’s largest and most diverse publicly available, pixel-accurately and instance-specifically annotated street-level imagery dataset for empowering autonomous mobility and transport at the global scale.
- WEBVISION DATASET
The WebVision dataset is designed to facilitate the research on learning visual representation from noisy web data. Our goal is to disentangle the deep learning techniques from huge human labor on annotating large-scale vision dataset. We release this large scale web images dataset as a benchmark to advance the research on learning from web data, including weakly supervised visual representation learning, visual transfer learning, text and vision, etc.
- DukeMTMC4ReID
DukeMTMC4ReID dataset is new large-scale real-world person re-id dataset based on DukeMTMC.
- Person Re-identification Datasets
Person re-identification has drawn intensive attention in the computer vision society in recent decades. As far as we know, this page collects all public datasets that have been tested by person re-identification algorithms.
- MIT Saliency Benchmark
- How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks)
- PoseTrack: A Benchmark for Human Pose Estimation and Tracking
TOOLKITS
XGBoostLSS An extension of XGBoost to probabilistic forecasting
Netron is a viewer for neural network, deep learning and machine learning models.
Bring Deep Learning to small devices An open source deep learning platform for low bit computation
Albumentations fast image augmentation library and easy to use wrapper around other libraries.
FeatherCNN
FeatherCNN is a high performance inference engine for convolutional neural networks.Caffe
Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by the Berkeley Vision and Learning Center (BVLC) and by community contributors. Yangqing Jia created the project during his PhD at UC Berkeley. Caffe is released under the BSD 2-Clause license.Caffe2
Caffe2 is a deep learning framework made with expression, speed, and modularity in mind. It is an experimental refactoring of Caffe, and allows a more flexible way to organize computation.Caffe on Intel
This fork of BVLC/Caffe is dedicated to improving performance of this deep learning framework when running on CPU, in particular Intel® Xeon processors (HSW+) and Intel® Xeon Phi processorsTensorFlow
TensorFlow is an open source software library for numerical computation using data flow graphs. Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) that flow between them. This flexible architecture lets you deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device without rewriting code. TensorFlow also includes TensorBoard, a data visualization toolkit.MXNet
MXNet is a deep learning framework designed for both efficiency and flexibility. It allows you to mix the flavours of symbolic programming and imperative programming to maximize efficiency and productivity. In its core, a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly. A graph optimization layer on top of that makes symbolic execution fast and memory efficient. The library is portable and lightweight, and it scales to multiple GPUs and multiple machines.neon
neon is Nervana’s Python based Deep Learning framework and achieves the fastest performance on modern deep neural networks such as AlexNet, VGG and GoogLeNet. Designed for ease-of-use and extensibility.Piotr’s Computer Vision Matlab Toolbox
This toolbox is meant to facilitate the manipulation of images and video in Matlab. Its purpose is to complement, not replace, Matlab’s Image Processing Toolbox, and in fact it requires that the Matlab Image Toolbox be installed. Emphasis has been placed on code efficiency and code reuse. Thanks to everyone who has given me feedback - you’ve helped make this toolbox more useful and easier to use.nvCaffe
A special branch of caffe is used on TX1 which includes support for FP16.dlib
Dlib is a modern C++ toolkit containing machine learning algorithms and tools for creating complex software in C++ to solve real world problems. It is used in both industry and academia in a wide range of domains including robotics, embedded devices, mobile phones, and large high performance computing environments. Dlib’s open source licensing allows you to use it in any application, free of charge.OpenCV
OpenCV is released under a BSD license and hence it’s free for both academic and commercial use. It has C++, C, Python and Java interfaces and supports Windows, Linux, Mac OS, iOS and Android. OpenCV was designed for computational efficiency and with a strong focus on real-time applications.CNNdroid
CNNdroid is an open source library for execution of trained convolutional neural networks on Android devices.tiny dnn
tiny-dnn is a C++11 implementation of deep learning. It is suitable for deep learning on limited computational resource, embedded systems and IoT devices.An introduction to this toolkit at《Deep learning with C++ - an introduction to tiny-dnn》by Taiga Nomi
CaffeMex
A multi-GPU & memory-reduced MAT-Caffe on LINUX and WINDOWSARCore ARCore is a platform for building augmented reality apps on Android. ARCore uses three key technologies to integrate virtual content with the real world as seen through your phone’s camera
CNTK Microsoft Cognitive Toolkit (CNTK), an open source deep-learning toolkit.
ONNX ONNX is a open format to represent deep learning models. With ONNX, AI developers can more easily move models between state-of-the-art tools and choose the combination that is best for them. ONNX is developed and supported by a community of partners.
PyToune is a Keras-like framework for PyTorch and handles much of the boilerplating code needed to train neural networks.
Deep Learning Studio - Desktop DeepCognition.ai is a single user solution that runs locally on your hardware. Desktop version allows you to train models on your GPU(s) without uploading data to the cloud. The platform supports transparent multi-GPU training for up to 4 GPUs. Additional GPUs are supported in Deep Learning Studio – Enterprise.
LEARNING/TRICKS/TIPS
- Training Tips for the Transformer Model
- Deep Learning Courses
- Backpropagation Algorithm
A website that explain how Backpropagation Algorithm works. - Deep Learning (textbook authored by Ian Goodfellow and Yoshua Bengio and Aaron Courville)
The Deep Learning textbook is a resource intended to help students and practitioners enter the field of machine learning in general and deep learning in particular. - Neural Networks and Deep Learning (online book authored by Michael Nielsen)
Neural Networks and Deep Learning is a free online book. The book will teach you about 1) Neural networks, a beautiful biologically-inspired programming paradigm which enables a computer to learn from observational data and 2) Deep learning, a powerful set of techniques for learning in neural networks. Neural networks and deep learning currently provide the best solutions to many problems in image recognition, speech recognition, and natural language processing. This book will teach you many of the core concepts behind neural networks and deep learning. - Computer Vision: Algorithms and Applications
This book is largely based on the computer vision courses that Richard Szeliski has co-taught at the University of Washington (2008, 2005, 2001) and Stanford (2003) with Steve Seitz and David Fleet. - Must Know Tips/Tricks in Deep Neural Networks
Many implementation details for DCNNs are collected and concluded. Extensive implementation details are introduced, i.e., tricks or tips, for building and training your own deep networks. - The zen of gradient descent
- Deriving the Gradient for the Backward Pass of Batch Normalization
- Reinforcement Learning: An Introduction
- An overview of gradient descent optimization algorithms
- Regularizing neural networks by penalizing confident predictions
- What you need to know about data augmentation for machine learning
Plentiful high-quality data is the key to great machine learning models. But good data doesn’t grow on trees, and that scarcity can impede the development of a model. One way to get around a lack of data is to augment your dataset. Smart approaches to programmatic data augmentation can increase the size of your training set 10-fold or more. Even better, your model will often be more robust (and prevent overfitting) and can even be simpler due to a better training set. - [Guide to deploying deep-learning inference networks and realtime object recognition tutorial for NVIDIA Jetson TX1]
- The Effect of Resolution on Deep Neural Network Image Classification Accuracy
The author explored the impact of both spatial resolution and training dataset size on the classification performance of deep neural networks in this post. - 深度学习调参的技巧
- CNN 怎么调参数
- 视频多目标跟踪当前(2014,2015,2016)比较好的算法有哪些
- 5 algorithms to train a neural network
- Towards Good Practices for Recognition & Detection
海康威视研究院 ImageNet2016 竞赛经验分享 - What are the differences between Random Forest and Gradient Tree Boosting algorithms
- 为什么现在的 CNN 模型都是在 GoogleNet、VGGNet 或者 AlexNet 上调整的
- 神经网络与深度学习
- ILSVRC2016 目标检测任务回顾(上)——图像目标检测(DET)
- ILSVRC2016 目标检测任务回顾(下)——视频目标检测(VID)
- How to Train a GAN? Tips and tricks to make GANs work
- 令人拍案叫绝的 Wasserstein GAN
- Mathematics for Computer Science
- 生成式对抗网络 GAN 的研究进展与展望
- A guide to receptive field arithmetic for Convolutional Neural Networks
- 见微知著:细粒度图像分析进展
- 目标跟踪相关资源
- Intro to Neural Networks and Machine Learning
- Tips for Training Recurrent Neural Networks
- A Gentle Introduction to Mini-Batch Gradient Descent and How to Configure Batch Size
- Learning To See(机器学习计算机视觉入门)(英文字幕)
- 37 Reasons why your Neural Network is not working
- My Neural Network isn’t working! What should I do?
- Tutorial on Deep Generative Models
- 卷积神经网络:从基础技术到研究前景
SKILLS
ABOUT CAFFE
- Set Up Caffe on Ubuntu14.04 64bit+NVIDIA GTX970M+CUDA7.0
- VS2013 配置 Caffe 卷积神经网络工具(64 位 Windows 7)——建立工程
- VS2013 配置 Caffe 卷积神经网络工具(64 位 Windows 7)——准备依赖库