TITLE: Chained Predictions Using Convolutional Neural Networks
AUTHER: Georgia Gkioxari, Alexander Toshev, Navdeep Jaitly
ASSOCIATION: UC Berkeley, Google
FROM: arXiv:1605.02346
CONTRIBUTIONS
- A chain model for structured outputs, such as human pose estimation. The output convolutional neural networks is a multiscale deconvolution that we called deception because of its relationship to deconvolution and inception models.
- Two formulations of the chain model is proposed. One is without weight sharing between different predictors (poses in images) and the other is with weight sharing (poses in videos).
METHOD
There are two formulations of the chain model in this work. The one used for single image is taken as an example here. It is a similar procedure in video version.
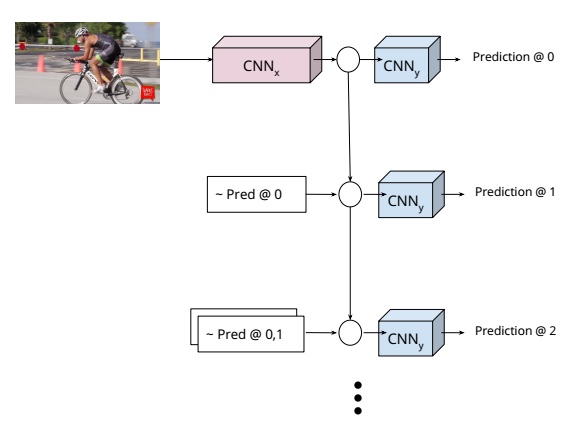
The inference stage is illustrated in the figure. The input is the image and the image is first fed to a CNN denoted as CNNx. For every stage, a joint of the person is localized by a CNN denoted as CNNy, denoted as “Predictio@0”. Then both the input and output of CNNy is used to predict next joint in the next stage. The procedure can be formalized as:
$$h_t=\sigma(w_t^h \ast h_{t-1}+\sum_{i=0}^{t-1}w_{i,t}^y \ast e(y_i))$$
$$P(Y_t=y_t|X,y_0,…,y_{t-1})=Softmax(m_t(h_t))$$
where $h_0$=CNNx(x), $e(\cdot)$ is a full neural net, $m_t$ is the operation of CNNy on $h_t$, and $P$ is the probability of the location of a joint.
ADVANTAGES
- Using chain models allows us to sidestep any assumptions about the joint distribution of the output variables.
- Jointly considering other structures can lead to better performance.
- Hand-crafted features are replaced by CNN, which can be learnt end-to-end.
DISADVANTAGES
- $e(\cdot)$ is not explained in this work.