
My Drawings [20160321 Eggplant]


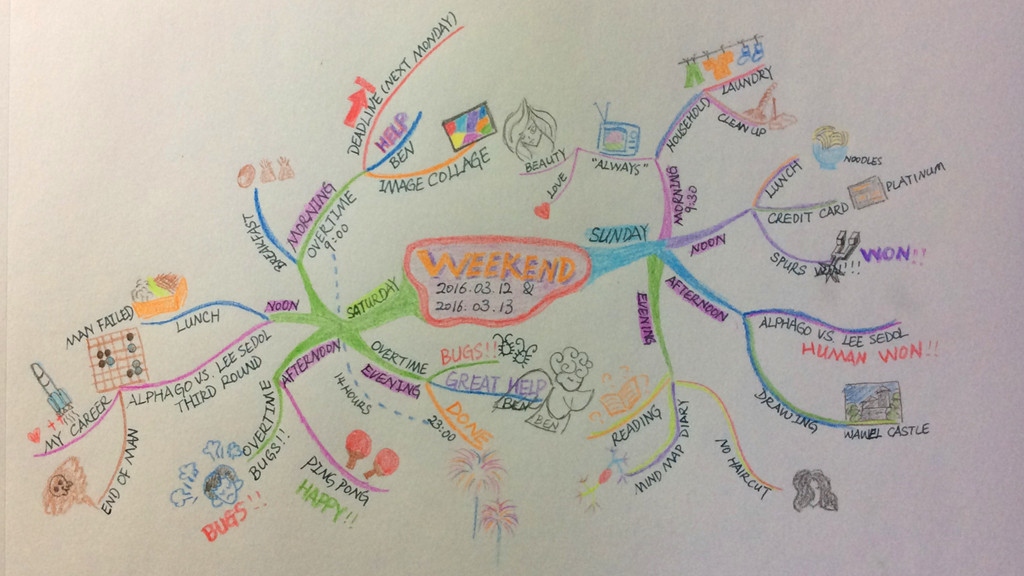
记个流水账吧。
2016年3月12日,早晨9:00加班至晚上23:00。其实这个周末我根本没有加班的计划,周五的时候打算回顺义,都要下班出发了,结果总部的一封邮件彻底打乱了原本的计划。周五的晚上就加班到晚上十一点了,但是任务太急,提交版本的deadline是周一,实现功能的代码也不是我自己写的,对工程很不熟悉,因此其实自己的效率是十分低下的。没有办法周六也只能赶工了,还好有代码的作者帮忙,其实同事的任务也很重,但还是花费一天时间帮我调程序,太感谢啦!按说周末加班挺苦的,我们组几个小伙伴都来了,气氛倒是挺活跃,大家嘻嘻哈哈的,干起活儿来效率还不错。中间大家还去活动室打了一会儿乒乓球,活动活动筋骨,挺提神的。不过到了晚上八九点钟以后,我就觉得大脑不怎么动了,这个时候结对编程的优势就集中体现了,即使一个人晕菜了,另一个还能帮忙给把把关。令人庆幸的是最终晚上十一点的时候,基本功能算是实现了,周一也能交差了,真是累死人啊。
2016年3月13日,主题:休闲娱乐。本来做好了周末要加班两天的思想准备的,幸运地在周六就完成了大部分工作,周日的主题就变成休闲娱乐了,幸福就这样降临了。早晨当然要睡个懒觉,即使醒了也得在床上多磨蹭一会儿。九点半起来洗了衣服,打扫了一下房间,看一集《太阳的后裔》上午过得也就差不多了。中午打算下楼理发、吃饭,结果楼下的理发店今天没开门,只吃个饭就上去也不太对得起这么好的天气,就去银行逗留了一会儿,绑定了手机号,办了一张白金信用卡。帮我办业务的业务员一看我的公司名字,说以前在我们公司实习过,巧得是我们俩居然是在同一组工作,这大概就是缘分了。
回来看了马刺对雷霆的比赛,马刺这种老流氓也是没sei了,这个赛季目前为止56剩10负,发挥得很出色,今天的比赛也相当精彩,尤其是最后一节由落后到反超,再到锁定胜局,整体篮球的精髓被发挥得淋漓尽致。下午还关注了AlphaGo对阵李世石的围棋比赛,虽然已经输掉了前三盘,这一盘李世石强势反击,击败人工智能,可以看到各大媒体社区都欢呼雀跃。当AlphaGo在第一盘战胜李世石时,我就写了一则微博
虽然李世石大战阿尔法狗还有4局,但是总感觉昨天也算作是见证历史了,兴奋与恐惧并存。或许若干年后,当机器统治世界时,人类抵抗组织会指出:2016.03.09 —— the day when the darkest time in mankind history began.
不知道这个“笑话”以后会不会成为现实。
下午一边看比赛,还画了一幅画。画的内容是瓦维尔城堡的一角,临摹我照的一张照片。基本功其实挺差的,应该好好找一本书看看,也应该多画一画练习练习。现在还处于只能临摹的状态,不能凭空作画,说明脑子里对事物的了解还不够深,没有记住事物的特点。希望能够快快进步,后面还想画彩色铅笔画。
晚上看了一会儿书,把东尼·博赞的《思维导图》看完了,感觉现在自己可以画出一些东西,但是还不能完全体会思维导图带来的好处,估计自己还只停留在表面,还需要自己多练习多思考,或者再仔细读一读《思维导图》这本书。博客开头的配图就是刚刚完成的用思维导图记录的周末日记,这篇博客也可以看做是对这幅思维导图的解说。
因为周六休息的特别好,又是吃、又是睡大觉、又是休闲娱乐的,前一周的感冒好的差不多了,昨天早晨醒来时,嗓子也没那么疼了,顿时感觉心情大好。再一想下午还要和几个小伙伴一起去看电影吃饭,这日子也真是没治了,惬意得都不像话。
昨天下午看的电影《疯狂动物城》相当精彩,最初看到这个译名我真是无感,本来就决定迪斯尼近两年的动画质量一般,这个译名更让人觉得是范范之作。还好群众的眼光是雪亮的,在各大影迷社区里,这部电影的评分都是出奇得高,我们也很“有眼光”地选了这一部电影。这部电影也确实火爆,开场一个小时之前我们再买票的时候就只剩第一排还有空位了。虽然全程仰视,但是这部电影真的值,再说还治颈椎病呢。

说说印象最深刻的几个场景吧:
兔子是有史以来第一个出身于兔子种族的警察,本来满怀一腔热血,决心干出一番大事业。到了警局兔子却被分配去做交通协管员,在路上给停车超时的汽车贴罚单,而事实上警局里有多宗大案要办,兔子内心的落差真是太大了。还好兔子没有沉沦,干劲满满的去贴罚单。想想看,也许很多初入职场的年轻人都经历过如此的境遇,很多人也许是一副闷闷不得志的样子,但是真的应该先从基础的事情做起。好像我们做图像的,不挑个几万张的样本,你可能连样本分布都搞不清。
兔子将动物野蛮化的消息和自己对这一事件的推断公布于媒体,这导致了动物城的极大恐慌,并带来了素食动物对肉食动物的歧视。兔子没有想到自己不成熟的行为导致了如此巨大的反响,而且也破坏了狐狸对兔子刚刚建立起来的信任。这是对现实世界的深刻反映,参与大众媒体的信息公布方和信息传播方或许都该仔细思考一下,一则消息是否是公众可以接受的,一则消息的公布时机是什么,一则消息的可信度有多高等等。
另外还有一些十分有趣的镜头。例如电影中对《教父》的致敬简直太到位了,Mr Big的配音和形象是对马龙·白兰度的夸张展现,很长一段剧情也都模仿了《教父》中的剧情。由各种矛盾制造的笑料,剧情的紧迫和慢吞吞的树懒,本应该敏捷如闪电的猎豹却变得贪吃且肥胖,本来一本正经且身材魁梧的公牛局长在偷看偶像视频时却表现出一副少女心。兔子用的手机logo为被咬掉一口的胡萝卜……
除了致敬和笑料,电影画面也十分精美,充满了各种奇观感受。整个故事充满了对现实的批判,很有深度,剧情也有反转,虽然随着故事的展开,观众还是可以猜出结尾,但是不影响观众对精彩程度的评价。《疯狂动物城》算是近两年迪斯尼不可多得的一部良心制作,强烈推荐!
悠闲自得的周末。
早晨起来随便收拾了收拾就已经快到午饭时间了,刚好室友去加班,中午吃什么就很随意了。特别喜欢这种不受限制的选择题,不必要考虑别人的喜好和倾向,自己选择吃得简单还是复杂,吃得清淡还是浓重,可以尝试从来没有试过的烹饪方法,反正“黑暗料理”煮熟了也不会死人。这不中午我就吃了室友最不喜欢,而我最喜欢的面食。
为什么喜欢面食呢,其实最主要的原因是懒。米饭必须配菜,做菜就麻烦了,一通准备就得花费好长时间。吃面食就容易的多,大不了买来直接就能吃,而且就面食本身而言就有好多花样,什么面条、包子、饺子、烙饼、馅饼……吃起来也快速,面条啼哩吐噜,包子饺子一口一个,烙饼馅饼手撕着就吃了,吃起来多痛快。要是吃得不讲究,吃完了都不用洗碗,这多好。

要是想做的复杂点,面食也可以特讲究,吃炸酱面的菜码就能摆一大桌子,吃春饼的话那料就更多了,什么炒合菜、京酱肉丝、酱牛肉、黄瓜丝、萝卜丝、小葱……中午就我一个,也犯不着那么费劲,但是搞得太简单了又有点亏待自己,那就不如来一碗炒烙饼,做着容易,自由搭配各种食材,虽然处理后的卖相没有处理前好,吃着的味道可是不赖。

吃完了午饭,休闲娱乐一下。看了两集最近热播的韩剧《太阳的后裔》,剧情上要求不高的话看着还不错,融合了战争场面、急诊医疗、爱情狗血,元素挺多元的,最重要的是男女主角颜值高啊,我对男主角没什么兴趣,主要就是女主角宋慧乔,这颜值保持得也太好了,不老传奇呀。再一个就是喜欢宋慧乔的衣着风格——简洁,朴素的纯色。不得不提的还有宋仲基的撩妹技能,感觉这个电视剧应该被分为技能类教学片。
看电视剧的一个好处就是有助于催眠,从三点一直睡到五点多,起来随便搞了点吃的。差不多也该看看有营养的东西了,有一句话说得好:被生活的烦恼困扰时,多半是因为最近想的太多却读书太少。因此趁着最近工作内容不多,空闲时间比较充裕,赶紧给自己充充电。前一阵因为“恐慌”买了一套书,是东尼博赞的《思维导图》系列丛书,昨天晚上加上今天一个傍晚刚好看完了第一本《启动大脑》。这套书的内容是何学习的方法论,学习如何学习很重要,但是在我的印象中好像并没有老师讲过相关的内容,大家都是在不断的摸索当中找到自己的学习方法。现在通过一些相关的培训,学习一些方法论,或许可以使得自己更加精进学习的技艺。再者就是通过系统的学习,可以让自己的学习有所目标,将学习的流程规范一下,通过不断的练习,让自己更高效的学习。
这一天过得惬意充实,晚上再记记流水账,准备睡觉!
TITLE: SuperCNN: A Superpixelwise Convolutional Neural Network for Salient Object Detection
AUTHER: Shengfeng He, Rynson W.H. Lau, Wenxi Liu, Zhe Huang, Qingxiong Yang Reid, Ian
FROM: IJCV2015
SOME DETAILS
Color Uniqueness Sequence is used to describe the color contrast of a Region. Given an image $I$ and the superpixels or regions \(R=\lbrace r_{1},…,r_{x},…,r_{N} \rbrace\), each region \(r_{x}\) contains a color uniqueness sequence $Q_{x}^{C} = \lbrace q_{1}^{c},…,q_{j}^{c},…,q_{N}^{c} \rbrace$. Each element, \(q_{x}^{c}\) is defined as
$$ q_{x}^{c} = t(r_{j})\cdot \vert C(r_{x})-C(r_{j}) \vert \cdot w(P(r_{x}),P(r_{j})) $$
where \(t(r_{j})\) counts the total number of pixels in region \(r_{j}\). \(\vert C(r_{x})-C(r_{j}) \vert\) is a 3D vector storing the absolute differences of each color channel. \(P(r_{x}\) is the mean position of region \(r_{j}\) and \(w(P(r_{x}),P(r_{j}))\) is defined as
$$ w(P(r_{x}),P(r_{j}))=exp(- \frac{1}{2\sigma_{s}^{2}}\Vert P(r_{x})-P(r_{j}) \Vert^{2} ) $$
The sequence \(Q_{x}^{C}\) is sorted by the spatial distance to region \(r_{x}\).
Color Distribution Sequence is a sequence \(Q_{x}^{D} = \lbrace q_{1}^{d},…,q_{j}^{d},…,q_{N}^{d} \rbrace\) with the element \(q_{j}^{d}\) defined as:
$$ q_{j}^{d} = t(r_{j})\cdot \vert P(r_{x})-P(r_{j}) \vert \cdot w(C(r_{x}),C(r_{j})) $$
where
$$ w(C(r_{x}),C(r_{j}))=exp(- \frac{1}{2\sigma_{s}^{2}}\Vert C(r_{x})-C(r_{j}) \Vert^{2} ) $$
the sequence is also sorted by the spatial distance.
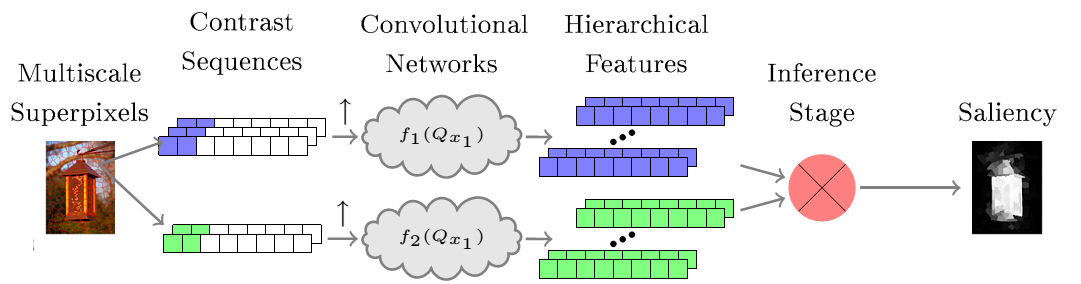
Network Structure is briefly illustrated as below:

Saliency Inference is first to get the \(N\) predicted saliency scores of the \(N\) regions. Because of the two kinds of sequences, two sets of scores \(S_{1} and S_{2}\) are predicted. The final saliency map can be obtained by:
$$ S(r_{x})=\prod_{u\in \lbrace 1,2\rbrace}v_c^{u} \cdot S_{u}(r_{x}) $$
最近一段时间过的不是很顺畅,不顺畅的方面在于所谓的“前途”方面。说说都有些什么吧,首先是以前参与的工作因为结果并不令人满意而处于半停止的状态;其次是自己负责的专利并没有被评为A1等级,而这个专利已经折磨了我八九个月了;最后是申请学校全部失败了。
这几处不顺畅让我突然感觉有点慌张。项目和专利是工作成果的最直接表现,现在总有一种竹篮打水一场空的感觉,两个东西什么都没有捞着。有点担心自己的绩效,这个和真金白银有关。也怀疑自己的能力,在东尼·博赞的《启动大脑》里有这样一段描述:
你完成了一项了不起的工作,人们开始说你是“杰出的、优秀的、令人吃惊的一个天才或明星”,称你的工作是“令人震惊的、最棒的、难以置信的、无与伦比的”。在一段时间内,你会很谦虚,但最后你也会认为你是优秀的。
我现在就有些怀疑自己,自己是否也陷入了上面的境地。当别人说你很棒的时候,其实是因为你遇到了好的机会,只不过因为运气,这个成绩落到了你的头上,而事实上任何人都可以取得同样的成绩。进一步的,在别人的称赞中,你最终也觉得自己是那个“优秀的、杰出的”人,从而让自己膨胀到认为你可以做好所有事。
慌张还来源于现在的状态,工作都没有进展,也无需准备申请学校的后续,进而导致待完成的事项变得稀少,一天下来有很多空闲的时间。忙的时候特别希望有空闲时间,可以让自己追踪一下现有最新发表的论文,看看自己感兴趣的东西。而且在忙的时候越发有一种动力,让自己忙里偷闲的去学习新知识。现在真的闲下来了,反而满脑子都是一些胡思乱想,总也静不下心来真正开始学习。自己渐渐地进入到了一种恶性循环之中,越是慌张就越静不下心,越是静不下心就越慌张。希望自己赶快脱离这种状态。
说到这种状态,更加让人不安的是前两天看到的一篇文章,叫做《你只是看上去很努力》,不知道我所谓的忙碌,是不是就是“看上去”的努力,而实际上是一种麻痹自我的手段。且不说这篇文章是不是一篇博人眼球的“鸡汤”,起码它让我进入到了自我怀疑的环境中。如果说这是我脑袋中其中一个“上进”的小人的想法,那另一个“堕落”的小人一直在跟我说:“你不快乐是因为你可以像猪一样懒,却无法像猪一样懒得心安理得”,他在催促我心安理得地享受一下空闲,不要把得失看得那么重。现在的我不知道哪一个才是正确的方向,到底应该是奋发向上、拼搏进取,还是应该收起来所谓的“梦想”,当一天和尚撞一天钟、差不多就可以了。说实话我多半还是会选择前者,那一个选项貌似更符合从小到大所受到的教育,然而现在我在想,这个选择的原因到底来自于“我想做”还是来自于“我应该做”。目前来看——无解。
想起一句北京顺义的广告词:离都市不远,距自然更近。我觉得这句话更适合形容南京城,城墙里是都市井肆的繁华世界,城墙外是山间溪水的世外桃源。
从城市的外观上就可以看出南京城的秀美。相对来说,北京城更加显示出一种等级森严的帝王气,一切都井井有条,皇城坐落在正中,城市是棋盘的布局,城墙是直来直往的。然而南京城却拥有一种含蓄委婉的气质,整座城市依江势山势展开,白墙黛瓦沿秦淮河错落有致地排列着,皇城歪歪地躺在一边,城墙也是婉转曲折,用优美的曲线将整个城市拥抱起来。也许这种城市的容貌无形之中就影响了人们的心态、说话的音调和行事的风格。
南京城里的繁华体现在商业的发达,秦淮河畔的酒家、饭馆总是熙熙攘攘,门庭若市。也许在白天还不太能考虑的到,但是只要天一擦黑,沿河的灯火点亮了,连着倒映在水里的明灯,将觥筹交错的气氛彰显得更加热闹。
南京城外则是另一番滋味,大大的一片玄武湖和紫金山,完全是自然风光的迤逦,然而谁又能想到大江大湖的烟云和山林的俊秀就只在城墙之外。在秦淮河畔喝了一顿碗鸭血粉丝汤之后,不如悠闲地到紫金山脚下散散步。就在城外不远处就可以欣赏灵谷的流萤、孝陵的梅花、紫霞湖的落日……
在南京呆久了,就不想离开了,既可以享受城市,又可以享受自然,整个城市都那么悠闲,不紧不慢地过活,去哪里二三十分钟就足够了,真是悠哉。说了这么多,或许是因为回到北京,我就得面对现实了,所以我才如此喜欢南京。也许南京也只是偶然,这个城市也可能是济南、扬州、或者无锡。
只是写些东西用来打发车上的时间。
列车是上午十点零五出发,现在是十点三十七分。这短短的三十分钟内,望着车窗外逐渐消失的城市,这脑子里还真是瞎想了不少东西。
第一个便是这天气,说到天气,估计现在的北京人都会特指空气质量了。毕竟夏天有空调,冬天有暖气,都热不着冻不着,就是吓人的雾霾让人没处躲没处藏。今天的空气质量虽说算不上特别优等,但也算很不错了,起码阳光明媚,天也是淡淡的蓝色。我 坐在靠窗的位置上,好歹也有个心情码码字。
第二个便是码字,说实话自己并不是一个喜欢写东西的人。上学的时候写作文估计是我最头疼的事了,中考高考作文的分数都低的很,每每想起都会说要是作文能多考个三五分会如何如何。现在工作了,最烦的就是写专利,虽说写专利跟写作文抒发情感不一样,不过一想到要写个好几十页也是抓头,往往都是能拖就拖,拖到最后借着最后期限激发出来的小宇宙才能完成。
最近倒是想着要多写写东西,动力的来源挺多。随便一想包括:自己有个个人网站;最近看到一个有意思的网站,叫做”简书”;不就之前上了一门英语写作的公开课。一个一个说说吧,个人网站真是自己弄着玩的,也没什么访问量,就是几个要好的朋友可能会去看看,上面的内容包括一些技术博客和生活记录,好久没有更新了,总得写点东西充充门面。”简书”这个网站其实挺文艺的,都是一些爱好写作的人发布的生活感悟,看了别人的文字,总觉得自己也应该多动动笔,记录一下生活,不然岂不是那些当时的感触都会随着时间渐渐消失,这样的人生会不会什么都不会留下呢,以后连个想回味的线索都没有。上英文写作公开课其实是因为当时正准备雅思考试,这门课的第一个作业就是写一小段作文,作文的主题是”作为作者的我”,我还从来没有从这个角度看待过自己,通过这个作业,我惊奇的发现原来自己早就是一个写作的人了,初中的每个寒暑假都被要求一天一篇日记,当有所经历或感悟时,写出来的东西也总能得到老师的积极评价。上了高中自己有写日记的习惯,现在看着那三个大硬皮本,里面可是有不少成长的烦恼。上了大学,在学生会写工作计划和总结,硕士期间也发了论文。写的东西其实挺多的,所以现在也觉得或许我并不是不能写。
说了码字,算是一种输出,那第三个便是输入——阅读。我一向认为没有输入就没有输出,这算是我的人生感悟了,与陌生人打交道时,我是一个为话题烦恼的人,只有当别人开始一个话题时,当他说了他的故事后,我才会想到我的故事。在工作中也一样,当我接受了别人的信息时,我更有可能提出有建设性的建议。所以我知道自己是一个没有输入就没有输出的人,甚至有了输入,输出的多少都很难说,按张大夫的话说就是:你们摩羯就是三脚踹不出来一个屁。所以现在想多写字,也是变相的督促自己多看看书。
以前自己会写一些技术博客,本来想着没看一篇文献就写一篇读书笔记,设想很不错,可惜坚持的不好,一个是有些文章读的不够深入,往往写不出什么东西;再一个就是有些时候工作太忙读文献的时间太少,或者干脆就没有读,往往过了一段时间以后,自己很难再回到阅读的状态里,一拖再拖就更加荒废了。除了业务相关的阅读,其实还应该加强一些其他方面的阅读,最近读了简书上的一些东西,发现自己在人文方面的素养太低了,经典名著没读过几本,人文社科的东西一看就困,现在应该让自己多思考思考哲学问题了。
刚刚还说了考雅思,其实当时是因为刚刚工作,算是从学生到职场的转型期,要说有什么特别大的压力,好像也没什么,但是总觉得不能太过放松,要保持竞争力。因此做了一个要出国读博士的决定,其实这个决定挺难的,毕竟时间和经济成本都不小,而且毕业回来之后会怎么发展也是未知数。但是为了让自己不至于退缩了,便趁着自己还有着一腔热情便赶紧报了雅思的培训班,雅思的成绩算是很不错了,综合一共7.5。从决定申请到现在一年多了,一切工作也都开展了,只是这结果有点差劲,给教授发套词信,回复的教授没几个,申请了几个学校,最近也陆续收到了拒信。想想这么个结果不怎么令人鼓舞,但是过程我知足了,每个周末不休息去上课,花力气读文献写科研计划书,不管怎么样起码英文能力有所提升。再者,即使不出国留学也可以活出自己的人生,只要不荒废了时间就好。
胡乱地今天就写这么多吧,十点三十七到十一点三十七,刚刚好一个小时。