TITLE: Learning to Detect Human-Object Interactions
AUTHOR: Yu-Wei Chao, Yunfan Liu, Xieyang Liu, Huayi Zeng, Jia Deng
ASSOCIATION: University of Michigan Ann Arbor, Washington University in St. Louis
FROM: arXiv:1702.05448
CONTRIBUTIONS
- HICO-DET is introduced, a dataset that provides more than 150K annotated instances of human-object pairs covering the 600 HOI categories in HICO
- A novel DNN-based framework for HOI detection is proposed. Human-Object Region-based Convolutional Neural Networks (HO-RCNN) outputs a pair of bounding boxes for each detected HOI instance. At the core of HO-RCNN is the Interaction Pattern, a novel DNN input that characterizes the spatial relations between two bounding boxes.
METHOD
HO-RCNN detects HOIs in two in two steps.
- Proposals of human-object region pairs are proposed using human and object detectors.
- Each human-object proposal is passed into a ConvNet to generate HOI classification scores.
The network adopts a multi-stream architecture to extract features on the detected humans, objects, and human-object spatial relations, as the following figure illustrated.
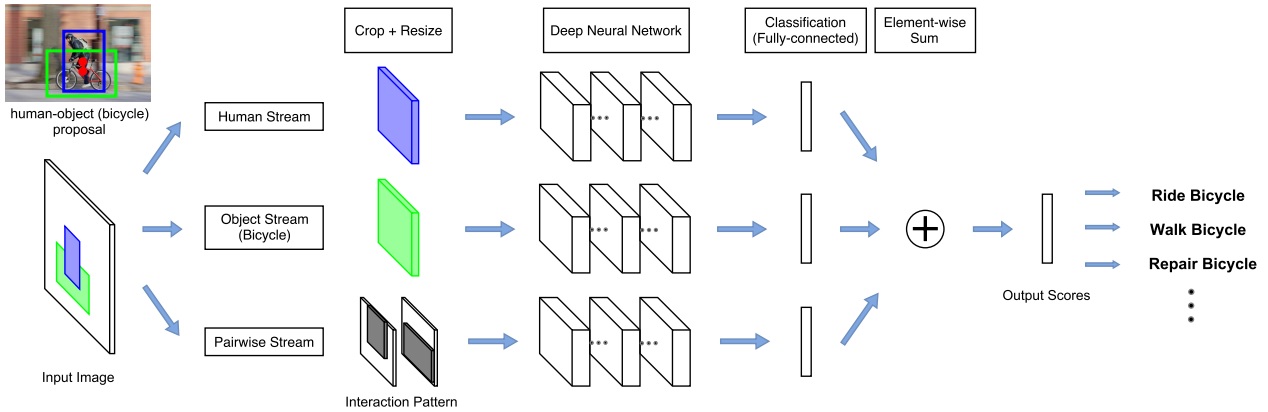
Human-Object Proposals
Assuming a list of HOI categories of interest (e.g. “riding a horse”, “eating an apple”) is given beforehand, bounding boxes for humans and the object categories of interest (e.g. “horse”, “apple”) are generated by detectors. Th human-object proposals are generated by pairing the detected humans and the detected objects of interest.
Multi-stream Architecture
The multistream architecture is composed of three streams
- The human stream extracts local features from the detected humans.
- The object stream extracts local features from the detected objects.
- The pairwise stream extracts features which encode pairwise spatial relations between the detected human and object.
The last layer of each stream is a binary classifier that outputs a confidence score for the HOI. The final confidence score is obtained by summing the scores over all streams.
Human and Object Stream
An image patch is cropped according to the bounding box (human/object) and is resized to a fixed size. Then the image patch is sent to a CNN to be classified and given an confidence for a HOI.
Pairwise Stream
Given a pair of bounding boxes, its Interaction Pattern is a binary image with two channels: The first channel has value 1 at pixels enclosed by the first bounding box, and value 0 elsewhere; the second channel has value 1 at pixels enclosed by the second bounding box, and value 0 elsewhere. In this work, the first bounding box is for humans, and the second bounding box is for objects.
The Interaction Patterns should be invariant to any joint translations of the bounding box pair. The pixels outside the “attention window”, i.e. the tightest window enclosing the two bounding boxes, are removed from the Interaction Pattern. the aspect ratio of Interaction Patterns should be fixed. Two methods are used. One wrap the patch, the other one extend the shorter side of the patch to meet the required ratio.
To extend to mulitple HOI classes, one binary classifier is trained for each HOI class at the last layer of each stream. The final score is summed over all streams separately for each HOI class.
SOME IDEAS
- Now the method is very similar with RCNN, maybe Fast-RCNN can also be used. Thus we can save much time for extracting features.
- How to exclude the condition of known HOI categories?