It’s been really great to see the wold.

It’s been really great to see the wold.
Yesterday I installed Qt Creator for Qt 5.8 on my Linux laptop. Everything was all right but I couldn’t to figure out how to conveniently start this IDE, needing to go to the bin directory to click the executable file. I’ve tried to start it from commond line, but the IDE will crash when openning a dialog window. So I decided to create a desktop shortcut to bypass.
To manually create a desktop shortcut, we can create a .desktop file and place it in either /usr/share/applications or ~/.local/share/applications. A typical .desktop file looks like the following.
[Desktop Entry]
Encoding=UTF-8
Version=1.0 # version of an app.
Name[en_US]=yEd # name of an app.
GenericName=GUI Port Scanner # longer name of an app.
Exec=java -jar /opt/yed-3.11.1/yed.jar # command used to launch an app.
Terminal=false # whether an app requires to be run in a terminal.
Icon[en_US]=/opt/yed-3.11.1/icons/yicon32.png # location of icon file.
Type=Application # type.
Categories=Application;Network;Security; # categories in which this app should be listed.
Comment[en_US]=yEd Graph Editor # comment which appears as a tooltip.
Using VIM is always a geek thing. However, it seems to be exausting to remember large numbers of commonds and shortcuts. Perhaps some really cool plugins can help alleviate the pain.
TITLE: Mask R-CNN
AUTHOR: Kaiming He, Georgia Gkioxari, Piotr Dollár, Ross Girshick
ASSOCIATION: Facebook AI Research
FROM: arXiv:1703.06870
Mask R-CNN is conceptually simple: Faster R-CNN has two outputs for each candidate object, a class label and a bounding-box offset; to this a third branch is added that outputs the object mask. The idea is illustrated in the following image.
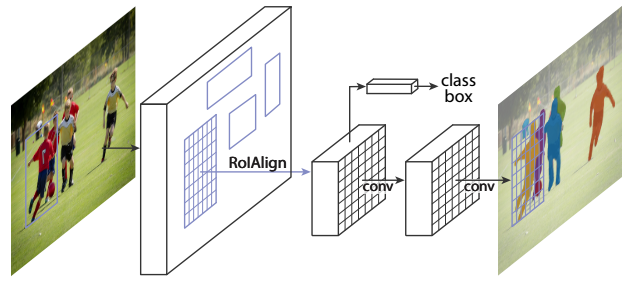
In order to avoid competition across classes, the mask branch has a $ Km^{2} $ dimensional output for each ROI, which endoces $ K $ binary masks of resolution $ m \times m $, one for each of the $ K $ classes. When training, for an ROI associated with ground-truth class $ k $, loss is only computed on the $k$-th mask.
An $ m \times m $ mask from each ROI is predicted using a small FCN network. The input of the small FCN network is an RoIAlign feature, which using bilinear interpolation to compute the exact values of the input feature at four regularly sampled locations in each ROI bin.
Tired after a business trip…

TITLE: FastMask: Segment Multi-scale Object Candidates in One Shot
AUTHOR: Hexiang Hu, Shiyi Lan, Yuning Jiang, Zhimin Cao, Fei Sha
ASSOCIATION: UCLA, Fudan University, Megvii Inc.
FROM: arXiv:1703.03872
The network architecture is illustrated in the following figure.

With the base feature map, a shared neck module is applied recursively to build feature maps with different scales. These feature maps are then fed to a one-by-one convolution to reduce their feature dimensionality. Then we extract dense sliding windows from those feature maps and do a batch normalization across all windows to calibrate and redistribute window feature maps. With a feature map downscaled by factor $m$, a sliding window of size $(k, k)$ corresponds to a patch of $(m \times k, m \times k)$ at original image. Finally, a unified head module is used to decode these window features and produce the output confidence score as well as object mask.
The neck module is actually used to downscale the feature maps so that features with different scales can be extracted.
There are another two choices. One is Max pooling neck, which produces uncalibrated feature in encoding pushing the mean of downscaled feature higher than original. The other one is Average pooling neck, which smoothes out discriminative feature during encoding, making the top feature maps appear to be blurry.
Residual neck is then proposed to learn parametric necks that preserve feature semantics. The following figure illustrates the method.
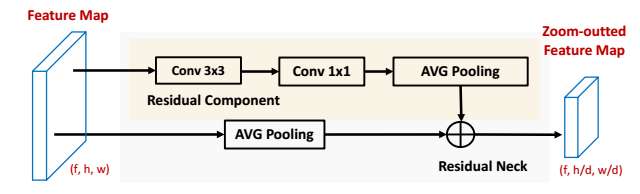
Given the feature map of a sliding window as the input, a spatial attention is generated through a fully connected layer, which takes the entire window feature to generate the attention score for each spatial location on the feature map. The spatial attention is then applied to window feature map via the element-wise multiplication across channels. Such operation enables the head module to enhance features on the salient region, where is supposed to be the rough location of the target object. Finally, the enhanced feature map will be fed into a fully connected laye to decode the segmentation mask of the object. This module is illustrated in the following figure.
The feature pyramid is sparse in this work because of the downscale operation. The sparse feature pyramid raises the probability that there exists no suitable feature maps for an object to decode, and also raises the risk of introducing background noises when the object is decoded from an unsuitable feature map with too larger receptive field. So salient region is introduced in this head. With the capability of paying attention to the salient region, a decoding head could reduce the noises from the backgrounds of a sliding window and thus produce high quality segmentation results when the receptive field is unmatched with the scale of object. Also the salient region attention has the tolerance to shift disturbance.
This photo reflects my life.
I just wanted to take a picture of the flowers at first. When I had a better look at this photo, it turned out to be very interesting that it happened to record an epitome of my life.
There are too books, one of which is about algorithms while the other one introducing how to sketch. I need to develop my own core ability to survive in this world with fierce competition. On the other hand, a hobby is needed to enjoy life, which can help me forget troubles for a while and look down to my own heart to be a better man. With those two, beautiful flowers bloom in my life.

How’s about this?? Maybe I’d like to start up my own business of bakery if I was unemployed. LOL…

人生就是不停地在做选择,抓起一些,就得放下一些。豁达的人经常问自己,我得到了什么,而不是我失去了什么?选择了一条路,自然会错过另一条路上的风景,与其眺望远处,不如珍惜眼前,每个地方都会春暖花开。
—— 杨坚华 《遇见德国》
这两天在读《遇见德国》,本来是为了猎取奇观的,看看有趣的文化冲突。但是读到以上这一段话的时候,却引起了我深深的共鸣。有些时候选择很多,但是我们需要对自己有足够的了解才能选择一条最适合自己的,而且迈出那一步也是相当需要勇气和技巧,所谓万事开头难。
The topic of this weekend is watching movies. For each movie, I wrote a one-setence comment.

CRIMSON TIDE: Resultant justice is on the basis of procedural justice, and there is not a conflict between them.

فروشنده: Life is like a play and good people is always touching you.

PATRIOTS DAY: Evils encourage us to care and love.

THE JUNGLE BOOK: Know who we are and act as who we are.

PASSENGERS: Human is a species of society.