Wow~~~ It’s the first time that I baked something. Hmm… perhaps I should call them caterpillar cookies :) Maybe in the future I can make cakes.

Wow~~~ It’s the first time that I baked something. Hmm… perhaps I should call them caterpillar cookies :) Maybe in the future I can make cakes.
TITLE: Learning to Detect Human-Object Interactions
AUTHOR: Yu-Wei Chao, Yunfan Liu, Xieyang Liu, Huayi Zeng, Jia Deng
ASSOCIATION: University of Michigan Ann Arbor, Washington University in St. Louis
FROM: arXiv:1702.05448
HO-RCNN detects HOIs in two in two steps.
The network adopts a multi-stream architecture to extract features on the detected humans, objects, and human-object spatial relations, as the following figure illustrated.
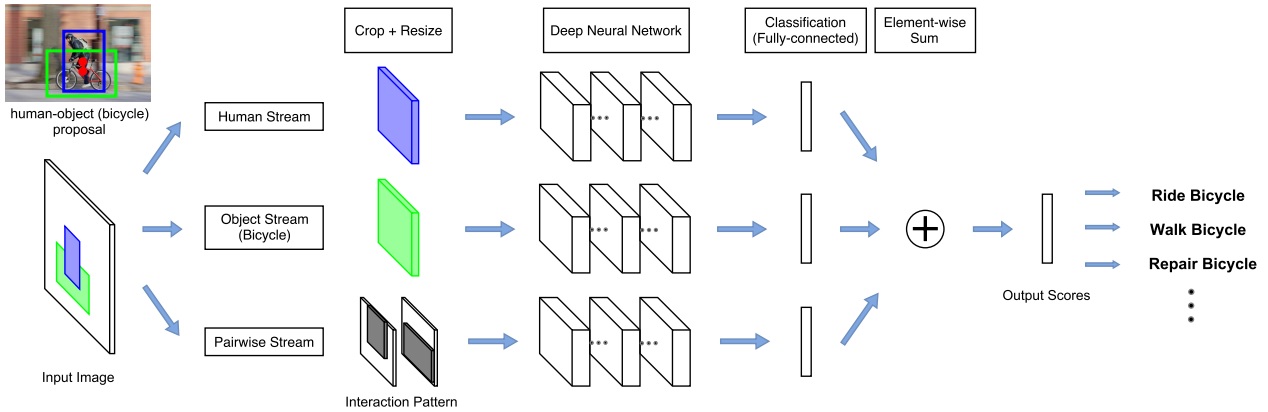
Assuming a list of HOI categories of interest (e.g. “riding a horse”, “eating an apple”) is given beforehand, bounding boxes for humans and the object categories of interest (e.g. “horse”, “apple”) are generated by detectors. Th human-object proposals are generated by pairing the detected humans and the detected objects of interest.
The multistream architecture is composed of three streams
The last layer of each stream is a binary classifier that outputs a confidence score for the HOI. The final confidence score is obtained by summing the scores over all streams.
Human and Object Stream
An image patch is cropped according to the bounding box (human/object) and is resized to a fixed size. Then the image patch is sent to a CNN to be classified and given an confidence for a HOI.
Pairwise Stream
Given a pair of bounding boxes, its Interaction Pattern is a binary image with two channels: The first channel has value 1 at pixels enclosed by the first bounding box, and value 0 elsewhere; the second channel has value 1 at pixels enclosed by the second bounding box, and value 0 elsewhere. In this work, the first bounding box is for humans, and the second bounding box is for objects.
The Interaction Patterns should be invariant to any joint translations of the bounding box pair. The pixels outside the “attention window”, i.e. the tightest window enclosing the two bounding boxes, are removed from the Interaction Pattern. the aspect ratio of Interaction Patterns should be fixed. Two methods are used. One wrap the patch, the other one extend the shorter side of the patch to meet the required ratio.
To extend to mulitple HOI classes, one binary classifier is trained for each HOI class at the last layer of each stream. The final score is summed over all streams separately for each HOI class.
Moved to new apartment.

TITLE: Adversarial Discriminative Domain Adaptation
AUTHOR: Eric Tzeng, Judy Hoffman, Kate Saenko, Trevor Darrell
ASSOCIATION: UC Berkeley, Stanford University, Boston University
FROM: arXiv:1702.05464
The main idea of this work is to find a map function project target data, the data for testing, to the source data domain, that are used for training. The training procedure is illustrated in the following figure.
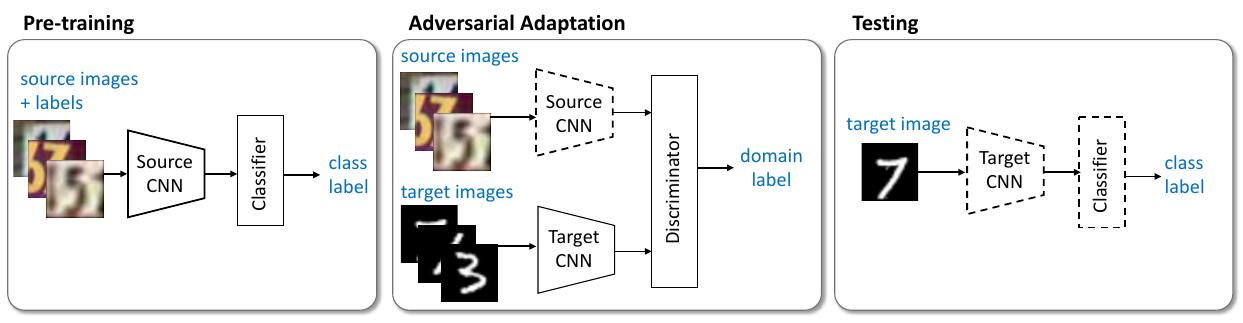
As the figure shows, first pre-train a source encoder CNN using labeled source image examples. Next, perform adversarial adaptation by learning a target encoder CNN such that a discriminator that sees encoded source and target examples cannot reliably predict their domain label. During testing, target images are mapped with the target encoder to the shared feature space and classified by the source classifier. Dashed lines indicate fixed network parameters.
The ADDA method can be formalized as:
$$ \min \limits_{M_{s}, C} \mathcal{L}{cls}(\mathbf{X{s}}, \mathbf{Y_{s}}) =
-\mathbb{E}{(\mathbf{x}{s}, y_{s})\sim(\mathbf{X}{s}, \mathbf{Y}{s})}[\sum_{k=1}^{K} \mathbf{1}{[k=y{s}]} \log C(M_s(\mathbf{x_s}))]$$
$$ \min \limits_{D} \mathcal{L}{ \mathbf{adv}D}(\mathbf{X{s}}, \mathbf{X{t}}, \mathbf{M_{s}}, \mathbf{M_{t}}) =
-\mathbb{E}{\mathbf{x}{s}\sim \mathbf{X}{s}} [\log D(M_s(\mathbf{x_s}))]
-\mathbb{E}{\mathbf{x}{t}\sim \mathbf{X}{t}} [\log (1-D(M_t(\mathbf{x_t})))]$$
$$ \min \limits_{M_s,M_t} \mathcal{L}{ \mathbf{adv}M}(\mathbf{X{s}}, \mathbf{X{t}}, D) =
-\mathbb{E}{\mathbf{x}{s}\sim \mathbf{X}_{t}} [\log D(M_t(\mathbf{x_t}))] $$
The first formula is a typical supervised learning. The second formula is just like what has been proposed in GAN. It is used to learn a discriminator to tell target data from source data. The first term can be ignored because $M_s$ is fixed. The third formula is used to learn a $M_t$ mapping data from targe domain to source domain.
I’ve been a great fun of ancient history and warfares since my childhood. Maybe the first enlightenment comes from the serial computer games Age of Empires. I didn’t know Joan of Arc until I played the campaign in Age of Empires II when I was 11 or 12 years old. The story in the ganme was so attractive that I searched who Joan of Arc was and what she did on Internet. I was touched by her patriotic acts and sacrifices. I even began to be interested in France history and wanted to study French in university, though I finally chose EE as my major and became an engineer in AI.
I played Age of Empires II HD a while this weekends because I found it was on sale in Steam. It brought me back to the time of my childhood. The memories of playing this game with my friends were recalled. We had fun playing this game, read stories of heroes and quarrelled about who was the greatest one in history. This is a classic computer game.

Forgiveness comes from courage.

原来“不转死全家”来自于《午夜凶铃》

春节之后好像更累。
工作上堆积了很多没有解决的问题,要么是程序有问题,要么是样本有问题,要么是模型有问题,总之是每天都紧赶慢赶,这边一下那边一下。连文章都没有时间好好看看,又有一种跟不上潮流的感觉了。
除了上班干活儿,另一个更让人心力憔悴的事就是看房子。自住房也快摇号了,一定要让我摇中了啊, 中了也就不转了,直接买一个,以后就在顺义混了。再一个就是看租的房子,还好眼急手快,直接出手了一个不错的一居室,就是打扫收拾搬家比较费劲。从下周开始蚂蚁搬家,每天从现住地搬点东西到公司,然后下班再搬到新租的房子,拖着空箱子回到现在住的地方。想想也够折腾,不过也没办法啦。希望搬过去之后能有精力再装饰一下新屋子,花了那么多钱租房子,总得让自己住的舒服点。
新年加油吧!
TITLE: DSSD: Deconvolutional Single Shot Detector
AUTHER: Cheng-Yang Fu, Wei Liu, Ananth Ranga, Ambrish Tyagi, Alexander C. Berg
FROM: arXiv:1701.06659
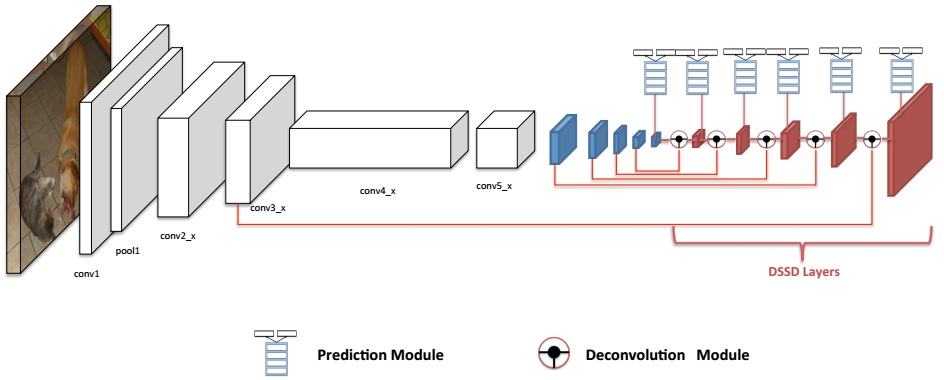
This is a successive work of SSD. Compared with original SSD, DSSD (Deconvolutional Single Shot Detector) adds additional deconvolutional layers and more sophisticated structure for category classifiction and bounding box coordinates regression. As shown in the following figure, the part till blue feature maps is same with original SSD. Then Deconvolution Module and Prediction Module are applied.
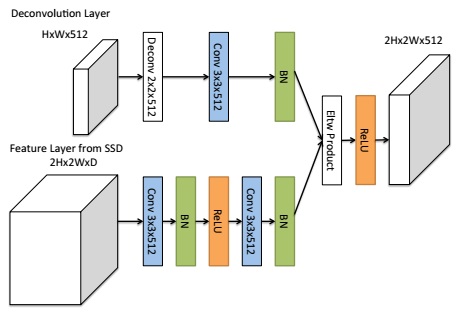
Recent works such as Beyond Skip Connections: Top-Down Modulation for Object Detection and Feature Pyramid Networks for Object Detection propose to incorporate fine details into the detection framework using deconvolutional layers and skip connections. DSSD utilizes this idea as well using Deconvolutional Module, shown in the following figure.
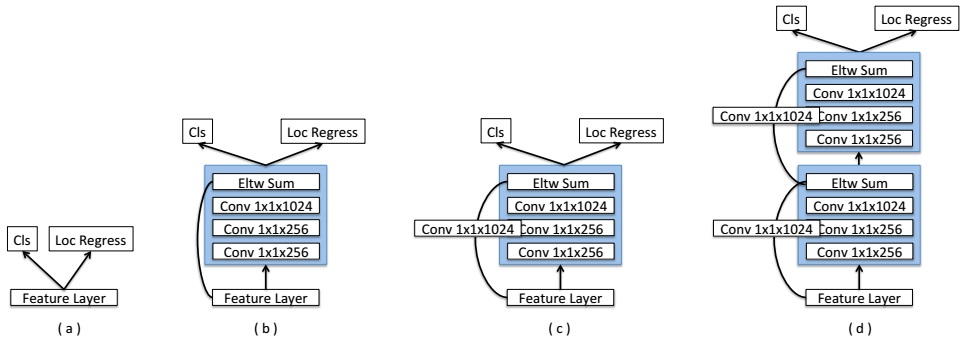
Several different structures for Prediction Module are proposed. These structures take the idea from ResNet as illustrated in the following figure.