It’s only 18 years till the story of I, Robot happens…

It’s only 18 years till the story of I, Robot happens…
TITLE: Pixel Objectness
AUTHOR: Suyog Dutt Jain, Bo Xiong, Kristen Grauman
ASSOCIATION: The University of Texas at Austin
FROM: arXiv:1701.05349
An end-to-end learning framework for foreground object segmentation is proposed. Given a single novel image, a pixel-level mask is produced for all “object-like” regions even for object categories never seen during training.
Given an RGB image of size $m \times n \times c$ as input, the problem is formulated as densely labeling each pixel in the images as eigher “object” or “background”. The output is a binary map of size $m \times n$.
Two different datasets are used including 1) one dataset with explicit boundary-level annotations and 2) one dataset with implicit imagelevel object category annotations.
The network is first trained on a large scale object classification task, such as ImageNet 1000-category classification. This stage can be regarded as training on an implicit labeled dataset. Its image representation has a strong notion of objectness built inside it, even though it never observes any segmentation annotations.
Then the network is trained on PASCAL 2012 segmentation dataset, which is an explicit labeled dataset. The 20 object labels are discarded, and mapped instead to the single generic “object-like” (foreground) label for training.
TITLE: Towards Accurate Multi-person Pose Estimation in the Wild
AUTHOR: George Papandreou, Tyler Zhu, Nori Kanazawa, Alexander Toshev, Jonathan Tompson, Chris Bregler, Kevin Murphy
ASSOCIATION: Google
FROM: arXiv:1701.01779
A method for multi-person detection and 2D keypoint localization in the wild is proposed.
The multi-person pose estimation system is a two step cascade, as illustrated in the Following figure.
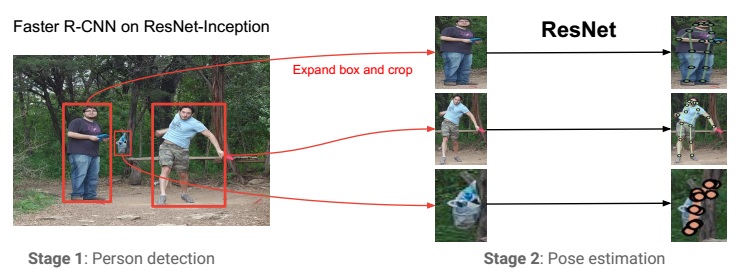
In the first stage, a person detector is used to produce a bounding box around each person instance. In the second stage, a pose estimator is produced to the image crop extracted around each detected person instance in order to localize its keypoints.
A Faster-RCNN system based on ResNet-Inception architecture is used for person box detection. The detector is first trained on 80 categories in COCO dataset. Then the model is further finetuned on dataset only with bounding boxes of person.
A combined classification and regression approach is adoptted. Each spatial position is first classified whether it is in the vicinity of keypoints (K types) or not (which is a K-channel “heatmap”), then a 2-D local offset vector is predicted to get a more precise estimate of the corresponding keypoint location. The following figure illustrates the procedure.
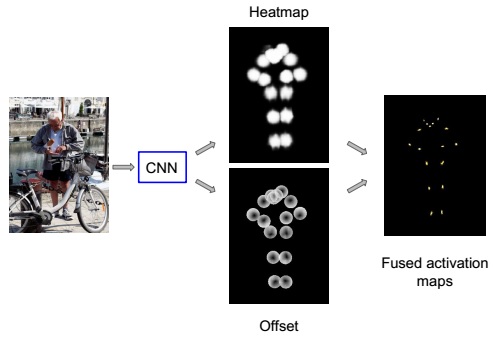
The bounding box is first adjusted to a fixed aspect ratio (height/width = 1.37) and the patch is cropped from the image and resized to 353*257. A ResNet with 101 layers is used to produce heatmap and offsets. The following figure shows an input and ground-truth output of the network.

生活里有好多大山要翻啊!

TITLE: YOLO9000: Better, Faster, Stronger
AUTHOR: Joseph Redmon, Ali Farhadi
ASSOCIATION: University of Washington, Allen Institute for AI
FROM: arXiv:1612.08242
The authors summarize the work as a better, faster and Stronger version of YOLO.
Batch Normalization
Batch Normalization is used in this work. The authors claim that it helps YOLO get more than 2% improvement in mAP. Even though, I doubt BN would help or it might even worsen the performance in real world applications because of my own experience using BN.
High Resolution Classifier
Instead finetuned on 224224 images, the classification network is finetuned on 448448 images, which helps the network perform better on higher resolution. This high resolution classification network gives an increase of almost 4% mAP.
Convolutional With Anchor Boxes
In YOLOv2, anchor boxes and FCN manner are also adopted. This enbles the YOLO generate much more boxes, which improves recall from 81% (69.5 mAP) to 88% (69.2 mAP).
Dimension Clusters
Prior works usally define the anchor boxes by hand, for example 1:1, 1:2(2:1) or 1:3(3:1) in SSD. In this work, the anchor boxes are defined by clustering. K-means clustering is used and the distance metric is defined based on IOU, which eliminates the effect caused by the actual size of boxes: larger boxes generate more error than smaller boxes using Euclidean distance.
Direct Location Prediction
Instead of predicting offsets to the center of the bounding box, YOLO9000 predicts location coordinates relative to the location of the grid cell, which bounds the ground truth to fall between 0 and 1. Then constrained location prediction is easier to learn.
Fine-Grained Features
In order to ultize finer grained features for localizing smaller objects, the authors add a passthrough layer that brings features from an earlier layer.
This is similar what has been done in ResNet.
Multi-Scale Training
Data of different resolutions are used to train the network. This regime forces the network to learn to predict well across a variety of input dimensions. This means the same network can predict detections at different resolutions.
Hierarchical Classification
A hierarchical prediction is built. Several nodes are added to build a tree. At each node, a semantic category is defined at a level. Thus images of different objects may be combined as one label because they belong to one higher level semantic label.
Joint Classification and Detection
Two datasets are used to train the large scale detetor. One is a traditional classification dataset, which contains a large number of categories. The other one is a detection dataset. When a detection image is seen, backpropagate loss as normal. For classification loss, only backpropagate loss at or above the corresponding level of the label.
日式治愈系电影《阪急电车》,每个与你擦肩而过的人都可能给你的生活带来变化,但是如果我们早已不关心身边的人了,那我们又如何从彼此之间获取能力呢。

小葵与高良健吾主演的漫改电影《手拉你》,每一个梦想都会败给现实,没有败给现实的梦想只存在于电影之中,甚至电影中的梦想也会败给现实。

想看《熔炉》很久了,一直没看,趁着元旦假期终于看了,当时看完有点后悔,因为实在太压抑,弄得我整个假期情绪都不好。
估计很多观众对《熔炉》的主角孔侑和郑裕美的关注是从《釜山行》开始的,相比较与《釜山行》,《熔炉》的质量可是高了很多,《熔炉》是根据韩国作家孔枝泳同名小说改编的剧情电影,根据真实事件改编,影片和小说的事实依据来源与2000年至2004年间发生于光州一所聋哑障碍人学校中的性暴力事件,
电影《熔炉》暴露出的社会福祉机构内存在着的侵害残障人人权的问题,也引发了韩国民众对残障人群体的集中关注效应。韩残障人团体等民间组织一致呼吁应对《社会福祉事业法》进行修订。
2011年12月29日,韩国国会通过了《社会福祉法事业法修订案》。修订后的社会福祉法规定,对触犯《性暴力特别法》和《儿童青少年性保护法》规定的犯罪行为,十年内不得从事相关业务,在职期间对使用社会福祉设施的人员实施同类犯罪的,将永远禁止从事社会福祉事业的经营管理业务。《社会福祉事业修订案》还规定了经营管理人员停止执行职务,强化国家和自法团体的指导和监督力度,提高社会福祉经营管理机构公益性和透明性等措施。
电影中暴露出的光州仁和学校虐待和性侵害学生事件,也引发人们对学生人权和性侵犯问题的关注。韩政府为预防“熔炉”事件的再次发生,积极推动国会通过《教育公务员法修订案》。修订案规定对实施性犯罪的老师将处以100万韩元以上的罚金并予以清退。
2011年10月起,韩国教育科学技术部对全国所有寄宿型特殊教育学校和普通特殊教育学校实施联合检查,并成立预防对残障学生实施性侵犯的“常设监督团”。同时还将对幼儿园、学校等教育机关从业人员的性犯罪经历进行调查。
韩国各级教育机关对残障人学生性侵害现状进行调查,并加强性教育以防止再次发生类似事件。韩国京畿道、光州、首尔等城市也相继出台《学生人权保护条例》禁止间接体罚,禁止性别歧视等。
电影当中给我冲击最大的一幕是叫陈侑利的聋哑女孩的笑容,正当大家因为庭审不顺利、施暴者很可能逍遥法外而愁眉苦脸、毫无胃口可言,小女孩却依然胃口大开,吃得满脸都是炸酱面,那笑容让人看到了一种希望,也让人更加对他们的遭遇感到心痛,对施暴者更加痛恨,这一幕真的让人百感交集。

春饼是北京吃食中最好吃的一种,我们全家一直都这么认为,吃起来简直没有够,年年做,年年吃,年年夸。
春饼的妙处在于它的综合效应
春饼表面上是混合物,八样东西,放在薄饼里,一裹,吃起来居然味道全变,神了。
这是春饼的非凡之处。
——舒乙《春饼》
真的,春饼也是我的最爱。有些地方用蒸出来的饼,我家里吃一般都是烙饼,估计是烙饼放的油多一点,总觉得烙饼吃着更香。每次吃都得吃撑还不愿意停,好像一吃春饼饭量都得变大一倍。家里吃的话一般炒一盘豆芽、炒几个鸡蛋、切点黄瓜丝和萝卜丝、再手撕一根葱、切点熟食、拌一晚麻酱,各夹一筷子用饼一卷,三四口嚼完,那叫一个香。在外面吃馆子,我会特意回去吃的列表很短,有一家春饼店是其中之一,每次去都点一盘炒合菜、一盘京酱肉丝和酱牛肉,再加两屉饼,没过一段时间不去都犯馋。
TITLE: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
AUTHOR: Zhe Cao, Tomas Simon, Shih-En Wei, Yaser Sheikh
ASSOCIATION: CMU
FROM: arXiv:1611.08050
This work is the successor of Convolutional Pose Machines. The network structure, which predict the part emergence heatmap and part aafinity field jointly, is illustrated in the following figure. We can compare it with previous work.
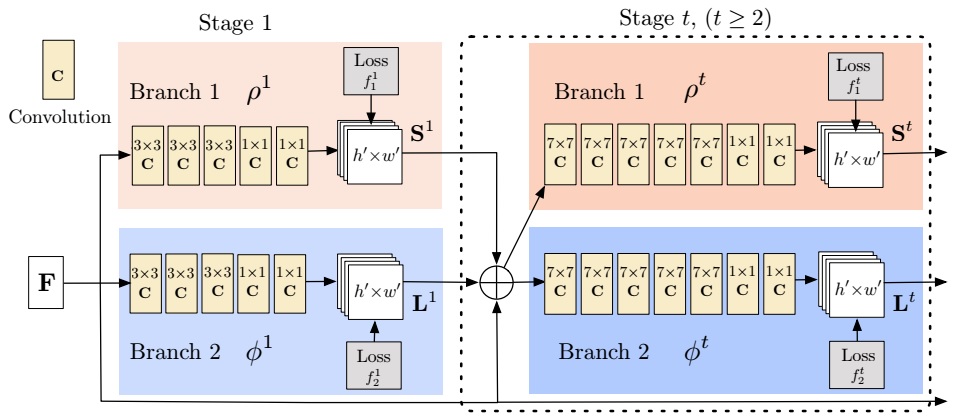
Similar with previous work, the network works as sequence learning scheme. One of the branch predicts confidence maps for part detection, while the other one predicts part affinity fields for part association.
At each location $ \mathbf{P} $, the value of the confidence $ S_{j}^{\ast}(\mathbf{P}) $ for a part type $ j $ is defined as
$$ S_{j}^{\ast}(\mathbf{P}) = \max \limits_{k} S_{j,k}^{\ast}(\mathbf{P}) $$
It means that for every type of part, a heatmap is predicted with multiple highlight areas, indicating the emergence of a part instance.
If we consider a single limb, let $$ \mathbf{x}{j_1,k} $$ and $$ \mathbf{x}{j_{2},k} $$ be the position of body parts $$ j_{1} $$ and $$ j_{2} $$ from the limb class $$ c $$ for a person $$ k $$ on the image. $$ l_{c,k} = \Vert \mathbf{x}{j{2},k} - \mathbf{x}{j{1},k} \Vert_{2} $$ is the length of the limb, and $$ \mathbf{v} = l^{−1}{c,k}(\mathbf{x}{j_{2},k} - \mathbf{x}{j{1},k}) $$ is the unit vector in the direction of the limb. The ideal part affinity vector field, $$ L^{∗}_{c,k} $$, at an image point $$ \mathbf{P} $$ as
$$ \mathbf{L}^{\ast}_{c,k}(\mathbf{P}) = \begin{cases}
\mathbf{v}& \text{if } \mathbf{P} \text{ on limb } c,k \
\mathbf{0}& \text{otherwise}
\end{cases} $$
Similar to confidence maps for part detection, part affinity fields are also predicted for all persons
$$ \mathbf{L}^{\ast}{c}(\mathbf{P}) = \frac{1}{n{p}} \sum_{k} \mathbf{L}^{\ast}_{c,k}(\mathbf{P}) $$
where $$n_{p}$$ is the number of non-zero vectos at point $$\mathbf{P}$$. The confidence score of each limb candidate is measured by
$$ E = \int_{u=0}^{u=1} \mathbf{L}{c}(\mathbf{P}(u)) \cdot \frac{\mathbf{d}{j_{2}}-\mathbf{d}{j{1}}}{\Vert \mathbf{d}{j{2}}-\mathbf{d}{j{1}} \Vert_{2}}du $$
where $$\mathbf{d}{j{1}}$$ and $$\mathbf{d}{j{2}}$$ are two detected body parts.
The last problem is to select different limbs linked in PAFs to combine as one person’s skeleton. This is a classical generalized maximum clique problem. I think in additional to the method mentioned in this paper, many other optimiaztion algorithms can be tried. These algorithms are well discussed in multi-object tracking problem.
TITLE: Convolutional Pose Machines
AUTHOR: Shih-En Wei, Varun Ramakrishna, Takeo Kanade, Yaser Sheikh
ASSOCIATION: CMU
FROM: arXiv:1602.00134
The following figure shows the comparison of traditional Pose Machine and Convolutional Pose Machine
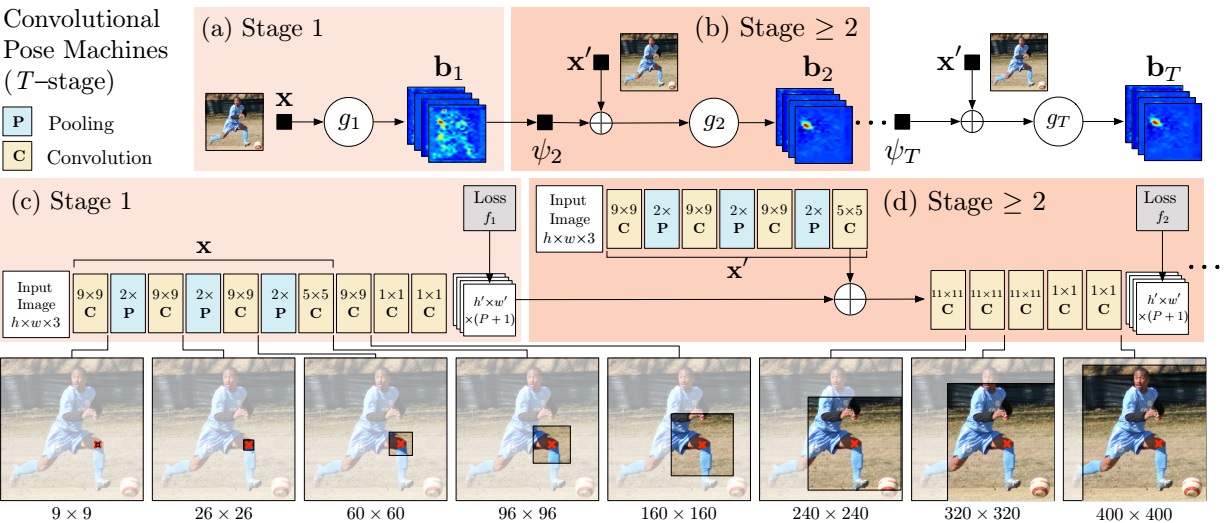
A pose machine consists of a sequence of multi-class predictors, $g_{t}(\cdot)$, that are trained to predict the location of each part in each level of the hierarchy. In each $stage$ $t \in {1…T}$, the classifiers $g_{t}$ predict beliefs for assigning a location to each part $Y_{p}=z, \forall z \in \mathbb{Z}$, where $\mathbb{Z}$ is the set of all locations in an image.
As illustrated in the figure (a) and (b), the image is first sent to $Stage$ $1$ and a belief map is predicted. Then the belief map and image features $x’$ are combined to sent to the following stage. As the procedure repeats, final result is predicted from the last $Stage$ $T$.
Convolutional Neural Network is naturally a sequence of stages if multiple losses and predictors are inserted at the intermediate layers. The (c) and (d) in the figure illustrated a convolutional pose machine. The sub-network in (c) plays the role of first stage. The shared network at the top-left corner in (d) is used to extract image features $x’$, which will be combined with the output of every $Stage$ $t-1$ and sent to $Stage$ $t$. In addition, the stacked convolutional layers’ perceptual field increases as deepening, which means that more contextual infomation is taken into consideration helping refine the output.
When training, every stage has its own loss function to predict parts. These losses work similar with the auxiliary classifiers in GoogleNet, which helps alleviate the problem caused by the vanishing of gradient. The network can be trained end-to-end. Compared with traditional pose machine, CMP is much easier to train. The visualization of the network can be found here