TITLE: Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking
AUTHER: Guanghan Ning, Zhi Zhang, Chen Huang, Zhihai He, Xiaobo Ren, Haohong Wang
ASSOCIATION: University of Missouri, University of Missouri
FROM: arXiv:1607.05781
CONTRIBUTIONS
- LSTM’s interpretation and regression capabilities of high-level visual features is explored.
- Neural network analysis is extended into the spatiotemporal domain for efficient visual object tracking.
METHOD
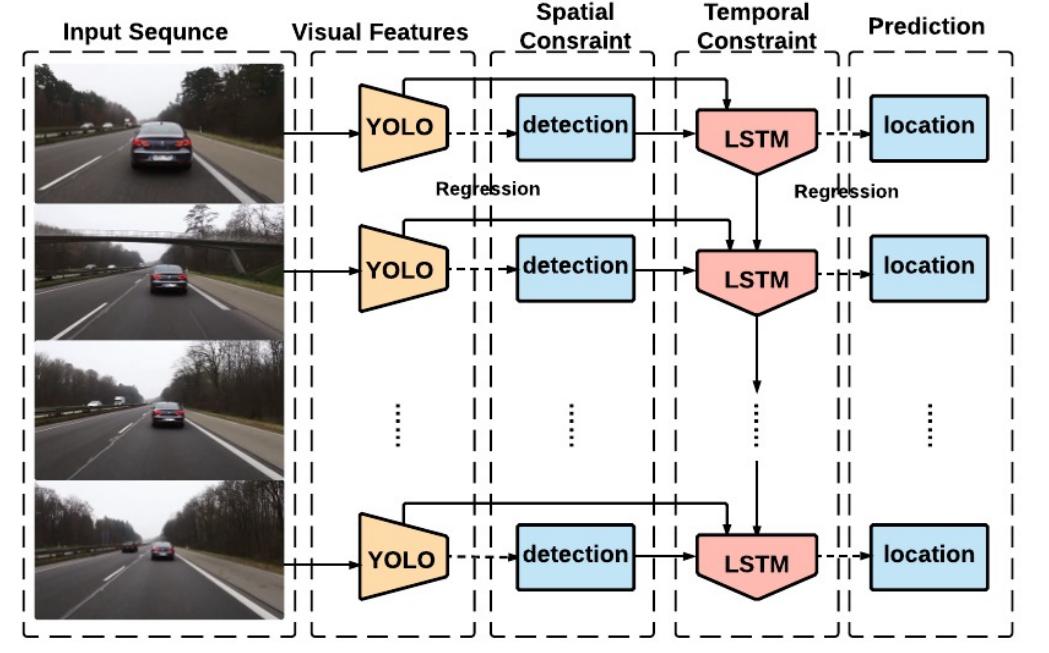
The main steps of the method is as follows:
- YOLO is used to collect rich and robust visual features, as well as preliminary location inferences.
- LSTM is used to regress the location of the object in video frames.
Some Details
There are two streams of data flowing into the LSTMs. One stream includes
- the feature representations from the convolutional layers $X_{t}$, for example the 4096-d feature from the fully-connected layer of VGG.
- the detection information $B_{t,i}$ from the fully connected layers. Thus, at each time-step t, we extract a feature vector of length 4096. We refer to these vectors as Xt .
Another stream includes
- the output of states from the last time-step $S_{t−1}$.
ADVANTAGES
- The processing speed is fast because of the YOLO algorithm.
- History of both location and appearance are considered.
- End-to-end training is used in tracking, which means that a unified system is introduced.
DISADVANTAGES
- YOLO may be not the best choice for detection.
- Only single object is processed.
OTHERS
- 4096-d feature is a representation for whole image, how about local representation.
- Is there a method of temporal-full convolutional operation on 3D video, similar with fully convolutional operation on 2D image?